U (kana)
う in hiragana or ウ in katakana (romanised u) is one of the Japanese kana, each of which represents one mora. In the modern Japanese system of alphabetical order, they occupy the third place in the modern Gojūon (五十音) system of collating kana. In the Iroha, they occupied the 24th position, between む and ゐ. In the Gojūon chart (ordered by columns, from right to left), う lies in the first column (あ行, "column A") and the third row (う段, "row U"). Both represent the sound [u͍]. In the Ainu language, the small katakana ゥ represents a diphthong, and is written as w in the Latin alphabet.
| Form | Rōmaji | Hiragana | Katakana |
|---|---|---|---|
| Normal a/i/u/e/o (あ行 a-gyō) |
u | う | ウ |
| uu ū |
うう うー |
ウウ ウー |
| Other additional forms | ||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||
| u | |||
|---|---|---|---|
| |||
| transliteration | u | ||
| hiragana origin | 宇 | ||
| katakana origin | 宇 | ||
| Man'yōgana | 宇 羽 于 有 卯 烏 得 | ||
| spelling kana | 上野のウ (Ueno no "u") | ||
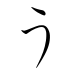

| kana gojūon | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| yori · koto · hentaigana | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The hiragana form with dakuten, ゔ, representing the sound "v", is rarely seen on older words, since the sound does not occur in native Japanese words. However, it is becoming more common with Western influences.
Derivation
Both う and ウ originate, via man'yōgana, from the kanji 宇 (pronounced u and meaning space).
Variant forms
Scaled-down versions of the characters (ぅ, ゥ) are used to create new morae that do not exist in the Japanese language, such as トゥ (tu). This convention is relatively new, and many older loanwords do not use it. For example, in the phrase Tutankhamun's cartouche, the recent loan cartouche uses the new phonetic technique, but the older loan Tutankhamun uses ツ (tsu) as an approximation:
Tsutankāmen no karutūshu
The character う is also used, in its full-sized form, to lengthen "o" sounds. For example, the word 構想 is written in hiragana as こうそう (kousou), pronounced kōsō. In a few words the character お (o) is used instead for morphological or historical reasons.
The character ウ can take dakuten to form ヴ (vu), a sound foreign to the Japanese language and traditionally approximated by ブ (bu).
In hentaigana a variant of う is appeared that written as cursive Kanji 宇.
Stroke order
 Stroke order in writing う |
 Stroke order in writing ウ |

The hiragana う is written in two strokes:
- At the top of the character, a short diagonal crook: proceeding diagonally downwards from the left, then reversing direction and ending at the lower left.
- A broad curving stroke: beginning at the left, rising slightly, then curving back and ending at the left.

The katakana ウ is written in three strokes:
- At the top of the character, a short vertical stroke, written from top to bottom.
- A similar stroke, but lower and positioned at the left.
- A broad angled stroke: beginning as a horizontal line written from left to right, then reversing direction and proceeding downwards from right to left as a curved diagonal. The horizontal line must touch both the other strokes. Apart from the short diagonal, the character is identical to フ.
Other communicative representations
| Japanese radiotelephony alphabet | Wabun code |
| 上野のウ Ueno no "U" |
 |
|
 |
 |
| Japanese Navy Signal Flag | Japanese semaphore | Japanese manual syllabary (fingerspelling) | Braille dots-14 Japanese Braille |
- Full Braille representation
| う / ウ in Japanese Braille | ||||
|---|---|---|---|---|
| う / ウ u | ゔ / ヴ vu | うう / ウー ū | ゔう / ヴー vū | +う / +ー chōon* |
* When lengthening "-u" or "-o" syllables in Japanese braille, a chōon is always used, as in standard katakana usage instead of adding an う / ウ.
| Preview | う | ウ | ウ | ぅ | ||||
|---|---|---|---|---|---|---|---|---|
| Unicode name | HIRAGANA LETTER U | KATAKANA LETTER U | HALFWIDTH KATAKANA LETTER U | HIRAGANA LETTER SMALL U | ||||
| Encodings | decimal | hex | decimal | hex | decimal | hex | decimal | hex |
| Unicode | 12358 | U+3046 | 12454 | U+30A6 | 65395 | U+FF73 | 12357 | U+3045 |
| UTF-8 | 227 129 134 | E3 81 86 | 227 130 166 | E3 82 A6 | 239 189 179 | EF BD B3 | 227 129 133 | E3 81 85 |
| Numeric character reference | う | う | ウ | ウ | ウ | ウ | ぅ | ぅ |
| Shift JIS[1] | 130 164 | 82 A4 | 131 69 | 83 45 | 179 | B3 | 130 163 | 82 A3 |
| EUC-JP[2] | 164 166 | A4 A6 | 165 166 | A5 A6 | 142 179 | 8E B3 | 164 165 | A4 A5 |
| GB 18030[3] | 164 166 | A4 A6 | 165 166 | A5 A6 | 132 49 151 53 | 84 31 97 35 | 164 165 | A4 A5 |
| EUC-KR[4] / UHC[5] | 170 166 | AA A6 | 171 166 | AB A6 | 170 165 | AA A5 | ||
| Big5 (non-ETEN kana)[6] | 198 170 | C6 AA | 198 253 | C6 FD | 198 169 | C6 A9 | ||
| Big5 (ETEN / HKSCS)[7] | 198 236 | C6 EC | 199 162 | C7 A2 | 198 235 | C6 EB | ||
| Preview | ゥ | ゥ | ゔ | ヴ | ||||
|---|---|---|---|---|---|---|---|---|
| Unicode name | KATAKANA LETTER SMALL U | HALFWIDTH KATAKANA LETTER SMALL U | HIRAGANA LETTER VU | KATAKANA LETTER VU | ||||
| Encodings | decimal | hex | decimal | hex | decimal | hex | decimal | hex |
| Unicode | 12453 | U+30A5 | 65385 | U+FF69 | 12436 | U+3094 | 12532 | U+30F4 |
| UTF-8 | 227 130 165 | E3 82 A5 | 239 189 169 | EF BD A9 | 227 130 148 | E3 82 94 | 227 131 180 | E3 83 B4 |
| Numeric character reference | ゥ | ゥ | ゥ | ゥ | ゔ | ゔ | ヴ | ヴ |
| Shift JIS (plain)[1] | 131 68 | 83 44 | 169 | A9 | 131 148 | 83 94 | ||
| Shift JIS (KanjiTalk 7)[8] | 131 68 | 83 44 | 169 | A9 | 136 104 | 88 68 | 131 148 | 83 94 |
| Shift JIS-2004[9] | 131 68 | 83 44 | 169 | A9 | 130 242 | 82 F2 | 131 148 | 83 94 |
| EUC-JP (plain)[2] | 165 165 | A5 A5 | 142 169 | 8E A9 | 165 244 | A5 F4 | ||
| EUC-JIS-2004[10] | 165 165 | A5 A5 | 142 169 | 8E A9 | 164 244 | A4 F4 | 165 244 | A5 F4 |
| GB 18030[3] | 165 165 | A5 A5 | 132 49 150 53 | 84 31 96 35 | 129 57 166 54 | 81 39 A6 36 | 165 244 | A5 F4 |
| EUC-KR[4] / UHC[5] | 171 165 | AB A5 | 171 244 | AB F4 | ||||
| Big5 (non-ETEN kana)[6] | 198 252 | C6 FC | 199 174 | C7 AE | ||||
| Big5 (ETEN / HKSCS)[7] | 199 161 | C7 A1 | 199 240 | C7 F0 | ||||
| Preview | ㋒ | |
|---|---|---|
| Unicode name | CIRCLED KATAKANA U | |
| Encodings | decimal | hex |
| Unicode | 13010 | U+32D2 |
| UTF-8 | 227 139 146 | E3 8B 92 |
| Numeric character reference | ㋒ | ㋒ |
| Look up う, ぅ, ウ, or ゥ in Wiktionary, the free dictionary. |
References
- Unicode Consortium (2015-12-02) [1994-03-08]. "Shift-JIS to Unicode".
- Unicode Consortium; IBM. "EUC-JP-2007". International Components for Unicode.
- Standardization Administration of China (SAC) (2005-11-18). GB 18030-2005: Information Technology—Chinese coded character set.
- Unicode Consortium; IBM. "IBM-970". International Components for Unicode.
- Steele, Shawn (2000). "cp949 to Unicode table". Microsoft / Unicode Consortium.
- Unicode Consortium (2015-12-02) [1994-02-11]. "BIG5 to Unicode table (complete)".
- van Kesteren, Anne. "big5". Encoding Standard. WHATWG.
- Apple Computer (2005-04-05) [1995-04-15]. "Map (external version) from Mac OS Japanese encoding to Unicode 2.1 and later". Unicode Consortium.
- Project X0213 (2009-05-03). "Shift_JIS-2004 (JIS X 0213:2004 Appendix 1) vs Unicode mapping table".
- Project X0213 (2009-05-03). "EUC-JIS-2004 (JIS X 0213:2004 Appendix 3) vs Unicode mapping table".