Te (kana)
て, in hiragana, or テ in katakana, is one of the Japanese kana, each of which represents one mora. Both represent [te].[1]
| Form | Rōmaji | Hiragana | Katakana |
|---|---|---|---|
| Normal t- (た行 ta-gyō) |
te | て | テ |
| tei tee tē |
てい, (てぃ) てえ, てぇ てー |
テイ, (ティ) テエ, テェ テー | |
| Addition dakuten d- (だ行 da-gyō) |
de | で | デ |
| dei dee dē |
でい, (でぃ) でえ, でぇ でー |
デイ, (ディ) デエ, デェ デー |
| Other additional forms | |||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| ||||||||||||||||||||||||||||||||||||
| te | |||
|---|---|---|---|
| |||
| transliteration | te | ||
| translit. with dakuten | de | ||
| hiragana origin | 天 | ||
| katakana origin | 天 | ||
| Man'yōgana | 堤 天 帝 底 手 代 直 | ||
| Voiced Man'yōgana | 代 田 泥 庭 伝 殿 而 涅 提 弟 | ||
| spelling kana | 手紙のテ (Tegami no "te") | ||
| unicode | U+3066, U+30C6 | ||
| braille | |||


| kana gojūon | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| yori · koto · hentaigana | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Stroke order
 Stroke order in writing て |
 Stroke order in writing テ |
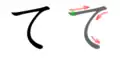
Stroke order in writing て
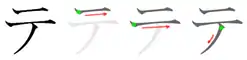
Stroke order in writing テ
Other communicative representations
| Japanese radiotelephony alphabet | Wabun code |
| 手紙のテ Tegami no "Te" |
▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄ |
|
|
 |
 | |
| Japanese Navy Signal Flag | Japanese semaphore | Japanese manual syllabary (fingerspelling) | Braille dots-12345 Japanese Braille |
- Full Braille representation
| て / テ in Japanese Braille | |||
|---|---|---|---|
| て / テ te | で / デ de | てい / テー tē/tei | でい / デー dē/dei |
| Preview | て | テ | テ | で | デ | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Unicode name | HIRAGANA LETTER TE | KATAKANA LETTER TE | HALFWIDTH KATAKANA LETTER TE | HIRAGANA LETTER DE | KATAKANA LETTER DE | |||||
| Encodings | decimal | hex | decimal | hex | decimal | hex | decimal | hex | decimal | hex |
| Unicode | 12390 | U+3066 | 12486 | U+30C6 | 65411 | U+FF83 | 12391 | U+3067 | 12487 | U+30C7 |
| UTF-8 | 227 129 166 | E3 81 A6 | 227 131 134 | E3 83 86 | 239 190 131 | EF BE 83 | 227 129 167 | E3 81 A7 | 227 131 135 | E3 83 87 |
| Numeric character reference | て | て | テ | テ | テ | テ | で | で | デ | デ |
| Shift JIS[2] | 130 196 | 82 C4 | 131 101 | 83 65 | 195 | C3 | 130 197 | 82 C5 | 131 102 | 83 66 |
| EUC-JP[3] | 164 198 | A4 C6 | 165 198 | A5 C6 | 142 195 | 8E C3 | 164 199 | A4 C7 | 165 199 | A5 C7 |
| GB 18030[4] | 164 198 | A4 C6 | 165 198 | A5 C6 | 132 49 153 49 | 84 31 99 31 | 164 199 | A4 C7 | 165 199 | A5 C7 |
| EUC-KR[5] / UHC[6] | 170 198 | AA C6 | 171 198 | AB C6 | 170 199 | AA C7 | 171 199 | AB C7 | ||
| Big5 (non-ETEN kana)[7] | 198 202 | C6 CA | 199 94 | C7 5E | 198 203 | C6 CB | 199 95 | C7 5F | ||
| Big5 (ETEN / HKSCS)[8] | 199 77 | C7 4D | 199 194 | C7 C2 | 199 78 | C7 4E | 199 195 | C7 C3 | ||
| Preview | ㋢ | 🈓 | ||
|---|---|---|---|---|
| Unicode name | CIRCLED KATAKANA TE | SQUARED KATAKANA DE | ||
| Encodings | decimal | hex | decimal | hex |
| Unicode | 13026 | U+32E2 | 127507 | U+1F213 |
| UTF-8 | 227 139 162 | E3 8B A2 | 240 159 136 147 | F0 9F 88 93 |
| UTF-16 | 13026 | 32E2 | 55356 56851 | D83C DE13 |
| Numeric character reference | ㋢ | ㋢ | 🈓 | 🈓 |
| Shift JIS (ARIB)[9] | 237 214 | ED D6 | ||
| GB 18030[4] | 129 57 211 52 | 81 39 D3 34 | 148 57 152 49 | 94 39 98 31 |
References
- "Tae Kim's Guide to Learning Japanese".
- Unicode Consortium (2015-12-02) [1994-03-08]. "Shift-JIS to Unicode".
- Unicode Consortium; IBM. "EUC-JP-2007". International Components for Unicode.
- Standardization Administration of China (SAC) (2005-11-18). GB 18030-2005: Information Technology—Chinese coded character set.
- Unicode Consortium; IBM. "IBM-970". International Components for Unicode.
- Steele, Shawn (2000). "cp949 to Unicode table". Microsoft / Unicode Consortium.
- Unicode Consortium (2015-12-02) [1994-02-11]. "BIG5 to Unicode table (complete)".
- van Kesteren, Anne. "big5". Encoding Standard. WHATWG.
- Scherer, Markus (2008). "ARIB Broadcast Symbols Unicode conversion mapping table using ICU's .ucm file format and representing ARIB codes in the Shift-JIS encoding scheme". Google.
This article is issued from Wikipedia. The text is licensed under Creative Commons - Attribution - Sharealike. Additional terms may apply for the media files.