Statistical model validation
In statistics, model validation is the task of confirming that the outputs of a statistical model are acceptable with respect to the real data-generating process. In other words, model validation is the task of confirming that the outputs of a statistical model have enough fidelity to the outputs of the data-generating process that the objectives of the investigation can be achieved.
Overview
Model validation can be based on two types of data: data that was used in the construction of the model and data that was not used in the construction. Validation based on the first type usually involves analyzing the goodness of fit of the model or analyzing whether the residuals seem to be random (i.e. residual diagnostics). Validation based on the second type usually involves analyzing whether the model's predictive performance deteriorates non-negligibly when applied to pertinent new data.
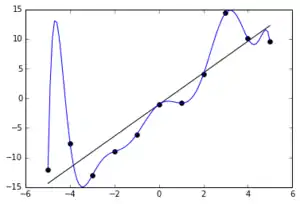
Validation based on only the first type (data that was used in the construction of the model) is often inadequate. An extreme example is illustrated in Figure 1. The figure displays data (black dots) that was generated via a straight line + noise. The figure also displays a curve, which is a polynomial chosen to fit the data perfectly. The residuals for the curve are all zero. Hence validation based on only the first type of data would conclude that the curve was a good model. Yet the curve is obviously a poor model: interpolation, especially between −5 and −4, would tend to be highly misleading; moreover, any substantial extrapolation would be bad.
Thus, validation is usually not based on only considering data that was used in the construction of the model; rather, validation usually also employs data that was not used in the construction. In other words, validation usually includes testing some of the model's predictions.
A model can be validated only relative to some application area.[1][2] A model that is valid for one application might be invalid for some other applications. As an example, consider the curve in Figure 1: if the application only used inputs from the interval [0, 2], then the curve might well be an acceptable model.
Methods for validating
When doing a validation, there are three notable causes of potential difficulty, according to the Encyclopedia of Statistical Sciences.[3] The three causes are these: lack of data; lack of control of the input variables; uncertainty about the underlying probability distributions and correlations. The usual methods for dealing with difficulties in validation include the following: checking the assumptions made in constructing the model; examining the available data and related model outputs; applying expert judgment.[1] Note that expert judgment commonly requires expertise in the application area.[1]
Expert judgment can sometimes be used to assess the validity of a prediction without obtaining real data: e.g. for the curve in Figure 1, an expert might well be able to assess that a substantial extrapolation will be invalid. Additionally, expert judgment can be used in Turing-type tests, where experts are presented with both real data and related model outputs and then asked to distinguish between the two.[4]
For some classes of statistical models, specialized methods of performing validation are available. As an example, if the statistical model was obtained via a regression, then specialized analyses for regression model validation exist and are generally employed.
Residual diagnostics
Residual diagnostics comprise analyses of the residuals to determine whether the residuals seem to be effectively random. Such analyses typically requires estimates of the probability distributions for the residuals. Estimates of the residuals' distributions can often be obtained by repeatedly running the model, i.e. by using repeated stochastic simulations (employing a pseudorandom number generator for random variables in the model).
If the statistical model was obtained via a regression, then regression-residual diagnostics exist and may be used; such diagnostics have been well studied.
See also
- All models are wrong
- Cross-validation (statistics)
- Identifiability analysis
- Internal validity
- Model identification
- Overfitting
- Predictive model
- Sensitivity analysis
- Spurious relationship
- Statistical conclusion validity
- Statistical model selection
- Statistical model specification
- Validity (statistics)
References
- National Research Council (2012), "Chapter 5: Model validation and prediction", Assessing the Reliability of Complex Models: Mathematical and statistical foundations of verification, validation, and uncertainty quantification, Washington, DC: National Academies Press, pp. 52–85CS1 maint: multiple names: authors list (link).
- Batzel, J. J.; Bachar, M.; Karemaker, J. M.; Kappel, F. (2013), "Chapter 1: Merging mathematical and physiological knowledge", in Batzel, J. J.; Bachar, M.; Kappel, F. (eds.), Mathematical Modeling and Validation in Physiology, Springer, pp. 3–19, doi:10.1007/978-3-642-32882-4_1.
- Deaton, M. L. (2006), "Simulation models, validation of", in Kotz, S.; et al. (eds.), Encyclopedia of Statistical Sciences, Wiley.
- Mayer, D. G.; Butler, D.G. (1993), "Statistical validation", Ecological Modelling, 68: 21–32, doi:10.1016/0304-3800(93)90105-2.
Further reading
- Barlas, Y. (1996), "Formal aspects of model validity and validation in system dynamics", System Dynamics Review, 12: 183–210, doi:10.1002/(SICI)1099-1727(199623)12:3<183::AID-SDR103>3.0.CO;2-4
- Good, P. I.; Hardin, J. W. (2012), "Chapter 15: Validation", Common Errors in Statistics (Fourth ed.), John Wiley & Sons, pp. 277–285
- Huber, P. J. (2002), "Chapter 3: Approximate models", in Huber-Carol, C.; Balakrishnan, N.; Nikulin, M. S.; Mesbah, M. (eds.), Goodness-of-Fit Tests and Model Validity, Springer, pp. 25–41
External links
- How can I tell if a model fits my data? —Handbook of Statistical Methods (NIST)
- Hicks, Dan (July 14, 2017). "What are core statistical model validation techniques?". Stack Exchange.