Spurious relationship
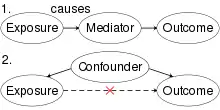
In statistics, a spurious relationship or spurious correlation[1][2] is a mathematical relationship in which two or more events or variables are associated but not causally related, due to either coincidence or the presence of a certain third, unseen factor (referred to as a "common response variable", "confounding factor", or "lurking variable").
Examples
An example of a spurious relationship can be found in the time-series literature, where a spurious regression is a regression that provides misleading statistical evidence of a linear relationship between independent non-stationary variables. In fact, the non-stationarity may be due to the presence of a unit root in both variables.[3][4] In particular, any two nominal economic variables are likely to be correlated with each other, even when neither has a causal effect on the other, because each equals a real variable times the price level, and the common presence of the price level in the two data series imparts correlation to them. (See also spurious correlation of ratios.)
Another example of a spurious relationship can be seen by examining a city's ice cream sales. The sales might be highest when the rate of drownings in city swimming pools is highest. To allege that ice cream sales cause drowning, or vice versa, would be to imply a spurious relationship between the two. In reality, a heat wave may have caused both. The heat wave is an example of a hidden or unseen variable, also known as a confounding variable.
Another commonly noted example is a series of Dutch statistics showing a positive correlation between the number of storks nesting in a series of springs and the number of human babies born at that time. Of course there was no causal connection; they were correlated with each other only because they were correlated with the weather nine months before the observations.[5] However Höfer et al. (2004) showed the correlation to be stronger than just weather variations as he could show in post reunification Germany that, while the number of clinical deliveries was not linked with the rise in stork population, out of hospital deliveries correlated with the stork population.[6]
In rare cases, a spurious relationship can occur between two completely unrelated variables without any confounding variable, as was the case between the success of the Washington Redskins professional football team in a specific game before each presidential election and the success of the incumbent President's political party in said election. For 16 consecutive elections between 1940 and 2000, the Redskins Rule correctly matched whether the incumbent President's political party would retain or lose the Presidency. The rule eventually failed shortly after Elias Sports Bureau discovered the correlation in 2000; in 2004, 2012 and 2016, the results of the Redskins game and the election did not match.[7][8][9]
Hypothesis testing
Often one tests a null hypothesis of no correlation between two variables, and chooses in advance to reject the hypothesis if the correlation computed from a data sample would have occurred in less than (say) 5% of data samples if the null hypothesis were true. While a true null hypothesis will be accepted 95% of the time, the other 5% of the times having a true null of no correlation a zero correlation will be wrongly rejected, causing acceptance of a correlation which is spurious (an event known as Type I error). Here the spurious correlation in the sample resulted from random selection of a sample that did not reflect the true properties of the underlying population.
Detecting spurious relationships
The term "spurious relationship" is commonly used in statistics and in particular in experimental research techniques, both of which attempt to understand and predict direct causal relationships (X → Y). A non-causal correlation can be spuriously created by an antecedent which causes both (W → X and W → Y). Mediating variables, (X → W → Y), if undetected, estimate a total effect rather than direct effect without adjustment for the mediating variable M. Because of this, experimentally identified correlations do not represent causal relationships unless spurious relationships can be ruled out.
Experiments
In experiments, spurious relationships can often be identified by controlling for other factors, including those that have been theoretically identified as possible confounding factors. For example, consider a researcher trying to determine whether a new drug kills bacteria; when the researcher applies the drug to a bacterial culture, the bacteria die. But to help in ruling out the presence of a confounding variable, another culture is subjected to conditions that are as nearly identical as possible to those facing the first-mentioned culture, but the second culture is not subjected to the drug. If there is an unseen confounding factor in those conditions, this control culture will die as well, so that no conclusion of efficacy of the drug can be drawn from the results of the first culture. On the other hand, if the control culture does not die, then the researcher cannot reject the hypothesis that the drug is efficacious.
Non-experimental statistical analyses
Disciplines whose data are mostly non-experimental, such as economics, usually employ observational data to establish causal relationships. The body of statistical techniques used in economics is called econometrics. The main statistical method in econometrics is multivariable regression analysis. Typically a linear relationship such as

is hypothesized, in which is the dependent variable (hypothesized to be the caused variable), for j = 1, ..., k is the jth independent variable (hypothesized to be a causative variable), and is the error term (containing the combined effects of all other causative variables, which must be uncorrelated with the included independent variables). If there is reason to believe that none of the s is caused by y, then estimates of the coefficients are obtained. If the null hypothesis that is rejected, then the alternative hypothesis that and equivalently that causes y cannot be rejected. On the other hand, if the null hypothesis that cannot be rejected, then equivalently the hypothesis of no causal effect of on y cannot be rejected. Here the notion of causality is one of contributory causality: If the true value , then a change in will result in a change in y unless some other causative variable(s), either included in the regression or implicit in the error term, change in such a way as to exactly offset its effect; thus a change in is not sufficient to change y. Likewise, a change in is not necessary to change y, because a change in y could be caused by something implicit in the error term (or by some other causative explanatory variable included in the model).






Regression analysis controls for other relevant variables by including them as regressors (explanatory variables). This helps to avoid mistaken inference of causality due to the presence of a third, underlying, variable that influences both the potentially causative variable and the potentially caused variable: its effect on the potentially caused variable is captured by directly including it in the regression, so that effect will not be picked up as a spurious effect of the potentially causative variable of interest. In addition, the use of multivariate regression helps to avoid wrongly inferring that an indirect effect of, say x1 (e.g., x1 → x2 → y) is a direct effect (x1 → y).
Just as an experimenter must be careful to employ an experimental design that controls for every confounding factor, so also must the user of multiple regression be careful to control for all confounding factors by including them among the regressors. If a confounding factor is omitted from the regression, its effect is captured in the error term by default, and if the resulting error term is correlated with one (or more) of the included regressors, then the estimated regression may be biased or inconsistent (see omitted variable bias).
In addition to regression analysis, the data can be examined to determine if Granger causality exists. The presence of Granger causality indicates both that x precedes y, and that x contains unique information about y.
Other relationships
There are several other relationships defined in statistical analysis as follows.
- Direct relationship
- Mediating relationship
- Moderating relationship
See also
Footnotes
- Burns, William C., "Spurious Correlations", 1997.
- Pearl, Judea. "UCLA 81st Faculty Research Lecture Series". singapore.cs.ucla.edu. Retrieved 2019-11-10.
- Yule, G. Udny (1926-01-01). "Why do we Sometimes get Nonsense-Correlations between Time-Series? A Study in Sampling and the Nature of Time-Series". Journal of the Royal Statistical Society. 89 (1): 1–63. doi:10.2307/2341482. JSTOR 2341482. S2CID 126346450.
- Granger, Clive W. J.; Ghysels, Eric; Swanson, Norman R.; Watson, Mark W. (2001). Essays in Econometrics: Collected Papers of Clive W. J. Granger. Cambridge University Press. ISBN 978-0521796491.
- Sapsford, Roger; Jupp, Victor, eds. (2006). Data Collection and Analysis. Sage. ISBN 0-7619-4362-5.
- Höfer, Thomas; Hildegard Przyrembel; Silvia Verleger (2004). "New evidence for the Theory of the Stork". Paediatric and Perinatal Epidemiology. 18 (1): 18–22. doi:10.1111/j.1365-3016.2003.00534.x. PMID 14738551.
- Hofheimer, Bill (October 30, 2012). "'Redskins Rule': MNF's Hirdt on intersection of football & politics". ESPN. Retrieved October 16, 2016.
- Manker, Rob (November 7, 2012). "Redskins Rule: Barack Obama's victory over Mitt Romney tackles presidential predictor for its first loss". Chicago Tribune. Retrieved November 8, 2012.
- Pohl, Robert S. (2013). Urban Legends & Historic Lore of Washington. The History Press. pp. 78–80. ISBN 978-1625846648.
References
- Banerjee, A.; Dolado, J.; Galbraith, J. W.; Hendry, D. F. (1993). Co-Integration, Error-Correction, and the Econometric Analysis of Non-Stationary Data. Oxford University Press. pp. 70–81. ISBN 0-19-828810-7.
- Pearl, Judea (2000). Causality: Models, Reasoning and Inference. Cambridge University Press. ISBN 0521773628.
External links
- Spurious correlations – a collection of examples