Successive over-relaxation
In numerical linear algebra, the method of successive over-relaxation (SOR) is a variant of the Gauss–Seidel method for solving a linear system of equations, resulting in faster convergence. A similar method can be used for any slowly converging iterative process.
It was devised simultaneously by David M. Young Jr. and by Stanley P. Frankel in 1950 for the purpose of automatically solving linear systems on digital computers. Over-relaxation methods had been used before the work of Young and Frankel. An example is the method of Lewis Fry Richardson, and the methods developed by R. V. Southwell. However, these methods were designed for computation by human calculators, requiring some expertise to ensure convergence to the solution which made them inapplicable for programming on digital computers. These aspects are discussed in the thesis of David M. Young Jr.[1]
Formulation
Given a square system of n linear equations with unknown x:

where:

Then A can be decomposed into a diagonal component D, and strictly lower and upper triangular components L and U:

where

The system of linear equations may be rewritten as:

for a constant ω > 1, called the relaxation factor.
The method of successive over-relaxation is an iterative technique that solves the left hand side of this expression for x, using previous value for x on the right hand side. Analytically, this may be written as:

where is the kth approximation or iteration of and is the next or k + 1 iteration of . However, by taking advantage of the triangular form of (D+ωL), the elements of x(k+1) can be computed sequentially using forward substitution:




Convergence
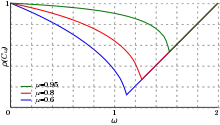



The choice of relaxation factor ω is not necessarily easy, and depends upon the properties of the coefficient matrix. In 1947, Ostrowski proved that if is symmetric and positive-definite then for . Thus, convergence of the iteration process follows, but we are generally interested in faster convergence rather than just convergence.



Convergence Rate
The convergence rate for the SOR method can be analytically derived. One needs to assume the following
- the relaxation parameter is appropriate:
- Jacobi's iteration matrix has only real eigenvalues
- Jacobi's method is convergent:
- a unique solution exists: .




Then the convergence rate can be expressed as[2]

where the optimal relaxation parameter is given by

Algorithm
Since elements can be overwritten as they are computed in this algorithm, only one storage vector is needed, and vector indexing is omitted. The algorithm goes as follows:
Inputs: A, b, ω Output:

Choose an initial guess to the solution repeat until convergence for i from 1 until n do for j from 1 until n do if j ≠ i then end if end (j-loop) end (i-loop) check if convergence is reached end (repeat)



- Note
- can also be written , thus saving one multiplication in each iteration of the outer for-loop.


Example
We are presented the linear system

To solve the equations, we choose a relaxation factor and an initial guess vector . According to the successive over-relaxation algorithm, the following table is obtained, representing an exemplary iteration with approximations, which ideally, but not necessarily, finds the exact solution, (3, −2, 2, 1), in 38 steps.


| Iteration | ||||
|---|---|---|---|---|
| 1 | 0.25 | -2.78125 | 1.6289062 | 0.5152344 |
| 2 | 1.2490234 | -2.2448974 | 1.9687712 | 0.9108547 |
| 3 | 2.070478 | -1.6696789 | 1.5904881 | 0.76172125 |
| ... | ... | ... | ... | ... |
| 37 | 2.9999998 | -2.0 | 2.0 | 1.0 |
| 38 | 3.0 | -2.0 | 2.0 | 1.0 |




A simple implementation of the algorithm in Common Lisp is offered below.
;; Set the default floating-point format to "long-float" in order to
;; ensure correct operation on a wider range of numbers.
(setf *read-default-float-format* 'long-float)
(defparameter +MAXIMUM-NUMBER-OF-ITERATIONS+ 100
"The number of iterations beyond which the algorithm should cease its
operation, regardless of its current solution. A higher number of
iterations might provide a more accurate result, but imposes higher
performance requirements.")
(declaim (type (integer 0 *) +MAXIMUM-NUMBER-OF-ITERATIONS+))
(defun get-errors (computed-solution exact-solution)
"For each component of the COMPUTED-SOLUTION vector, retrieves its
error with respect to the expected EXACT-SOLUTION vector, returning a
vector of error values.
---
While both input vectors should be equal in size, this condition is
not checked and the shortest of the twain determines the output
vector's number of elements.
---
The established formula is the following:
Let resultVectorSize = min(computedSolution.length, exactSolution.length)
Let resultVector = new vector of resultVectorSize
For i from 0 to (resultVectorSize - 1)
resultVector[i] = exactSolution[i] - computedSolution[i]
Return resultVector"
(declare (type (vector number *) computed-solution))
(declare (type (vector number *) exact-solution))
(map '(vector number *) #'- exact-solution computed-solution))
(defun is-convergent (errors &key (error-tolerance 0.001))
"Checks whether the convergence is reached with respect to the
ERRORS vector which registers the discrepancy betwixt the computed
and the exact solution vector.
---
The convergence is fulfilled if and only if each absolute error
component is less than or equal to the ERROR-TOLERANCE, that is:
For all e in ERRORS, it holds: abs(e) <= errorTolerance."
(declare (type (vector number *) errors))
(declare (type number error-tolerance))
(flet ((error-is-acceptable (error)
(declare (type number error))
(<= (abs error) error-tolerance)))
(every #'error-is-acceptable errors)))
(defun make-zero-vector (size)
"Creates and returns a vector of the SIZE with all elements set to 0."
(declare (type (integer 0 *) size))
(make-array size :initial-element 0.0 :element-type 'number))
(defun successive-over-relaxation (A b omega
&key (phi (make-zero-vector (length b)))
(convergence-check
#'(lambda (iteration phi)
(declare (ignore phi))
(>= iteration +MAXIMUM-NUMBER-OF-ITERATIONS+))))
"Implements the successive over-relaxation (SOR) method, applied upon
the linear equations defined by the matrix A and the right-hand side
vector B, employing the relaxation factor OMEGA, returning the
calculated solution vector.
---
The first algorithm step, the choice of an initial guess PHI, is
represented by the optional keyword parameter PHI, which defaults
to a zero-vector of the same structure as B. If supplied, this
vector will be destructively modified. In any case, the PHI vector
constitutes the function's result value.
---
The terminating condition is implemented by the CONVERGENCE-CHECK,
an optional predicate
lambda(iteration phi) => generalized-boolean
which returns T, signifying the immediate termination, upon achieving
convergence, or NIL, signaling continuant operation, otherwise. In
its default configuration, the CONVERGENCE-CHECK simply abides the
iteration's ascension to the ``+MAXIMUM-NUMBER-OF-ITERATIONS+'',
ignoring the achieved accuracy of the vector PHI."
(declare (type (array number (* *)) A))
(declare (type (vector number *) b))
(declare (type number omega))
(declare (type (vector number *) phi))
(declare (type (function ((integer 1 *)
(vector number *))
*)
convergence-check))
(let ((n (array-dimension A 0)))
(declare (type (integer 0 *) n))
(loop for iteration from 1 by 1 do
(loop for i from 0 below n by 1 do
(let ((rho 0))
(declare (type number rho))
(loop for j from 0 below n by 1 do
(when (/= j i)
(let ((a[ij] (aref A i j))
(phi[j] (aref phi j)))
(incf rho (* a[ij] phi[j])))))
(setf (aref phi i)
(+ (* (- 1 omega)
(aref phi i))
(* (/ omega (aref A i i))
(- (aref b i) rho))))))
(format T "~&~d. solution = ~a" iteration phi)
;; Check if convergence is reached.
(when (funcall convergence-check iteration phi)
(return))))
(the (vector number *) phi))
;; Summon the function with the exemplary parameters.
(let ((A (make-array (list 4 4)
:initial-contents
'(( 4 -1 -6 0 )
( -5 -4 10 8 )
( 0 9 4 -2 )
( 1 0 -7 5 ))))
(b (vector 2 21 -12 -6))
(omega 0.5)
(exact-solution (vector 3 -2 2 1)))
(successive-over-relaxation
A b omega
:convergence-check
#'(lambda (iteration phi)
(declare (type (integer 0 *) iteration))
(declare (type (vector number *) phi))
(let ((errors (get-errors phi exact-solution)))
(declare (type (vector number *) errors))
(format T "~&~d. errors = ~a" iteration errors)
(or (is-convergent errors :error-tolerance 0.0)
(>= iteration +MAXIMUM-NUMBER-OF-ITERATIONS+))))))
A simple Python implementation of the pseudo-code provided above.
import numpy as np
def sor_solver(A, b, omega, initial_guess, convergence_criteria):
"""
This is an implementation of the pseudo-code provided in the Wikipedia article.
Arguments:
A: nxn numpy matrix.
b: n dimensional numpy vector.
omega: relaxation factor.
initial_guess: An initial solution guess for the solver to start with.
convergence_criteria: The maximum discrepancy acceptable to regard the current solution as fitting.
Returns:
phi: solution vector of dimension n.
"""
step = 0
phi = initial_guess[:]
residual = np.linalg.norm(np.matmul(A, phi) - b) # Initial residual
while residual > convergence_criteria:
for i in range(A.shape[0]):
sigma = 0
for j in range(A.shape[1]):
if j != i:
sigma += A[i, j] * phi[j]
phi[i] = (1 - omega) * phi[i] + (omega / A[i, i]) * (b[i] - sigma)
residual = np.linalg.norm(np.matmul(A, phi) - b)
step += 1
print("Step {} Residual: {:10.6g}".format(step, residual))
return phi
# An example case that mirrors the one in the Wikipedia article
residual_convergence = 1e-8
omega = 0.5 # Relaxation factor
A = np.array([[4, -1, -6, 0],
[-5, -4, 10, 8],
[0, 9, 4, -2],
[1, 0, -7, 5]])
b = np.array([2, 21, -12, -6])
initial_guess = np.zeros(4)
phi = sor_solver(A, b, omega, initial_guess, residual_convergence)
print(phi)
Symmetric successive over-relaxation
The version for symmetric matrices A, in which

is referred to as Symmetric Successive Over-Relaxation, or (SSOR), in which

and the iterative method is

The SOR and SSOR methods are credited to David M. Young Jr..
Other applications of the method
A similar technique can be used for any iterative method. If the original iteration had the form

then the modified version would use

However, the formulation presented above, used for solving systems of linear equations, is not a special case of this formulation if x is considered to be the complete vector. If this formulation is used instead, the equation for calculating the next vector will look like

where . Values of are used to speed up convergence of a slow-converging process, while values of are often used to help establish convergence of a diverging iterative process or speed up the convergence of an overshooting process.



There are various methods that adaptively set the relaxation parameter based on the observed behavior of the converging process. Usually they help to reach a super-linear convergence for some problems but fail for the others.

Notes
- Young, David M. (May 1, 1950), Iterative methods for solving partial difference equations of elliptical type (PDF), PhD thesis, Harvard University, retrieved 2009-06-15
- Hackbusch, Wolfgang (2016). "4.6.2". Iterative Solution of Large Sparse Systems of Equations | SpringerLink. Applied Mathematical Sciences. 95. doi:10.1007/978-3-319-28483-5. ISBN 978-3-319-28481-1.
References
- This article incorporates text from the article Successive_over-relaxation_method_-_SOR on CFD-Wiki that is under the GFDL license.
- Abraham Berman, Robert J. Plemmons, Nonnegative Matrices in the Mathematical Sciences, 1994, SIAM. ISBN 0-89871-321-8.
- Black, Noel & Moore, Shirley. "Successive Overrelaxation Method". MathWorld.
- A. Hadjidimos, Successive overrelaxation (SOR) and related methods, Journal of Computational and Applied Mathematics 123 (2000), 177–199.
- Yousef Saad, Iterative Methods for Sparse Linear Systems, 1st edition, PWS, 1996.
- Netlib's copy of "Templates for the Solution of Linear Systems", by Barrett et al.
- Richard S. Varga 2002 Matrix Iterative Analysis, Second ed. (of 1962 Prentice Hall edition), Springer-Verlag.
- David M. Young Jr. Iterative Solution of Large Linear Systems, Academic Press, 1971. (reprinted by Dover, 2003)