Stepwise regression
In statistics, stepwise regression is a method of fitting regression models in which the choice of predictive variables is carried out by an automatic procedure.[1][2][3][4] In each step, a variable is considered for addition to or subtraction from the set of explanatory variables based on some prespecified criterion. Usually, this takes the form of a sequence of F-tests or t-tests, but other techniques are possible, such as adjusted R2, Akaike information criterion, Bayesian information criterion, Mallows's Cp, PRESS, or false discovery rate.
The frequent practice of fitting the final selected model followed by reporting estimates and confidence intervals without adjusting them to take the model building process into account has led to calls to stop using stepwise model building altogether[5][6] or to at least make sure model uncertainty is correctly reflected.[7][8]
Main approaches
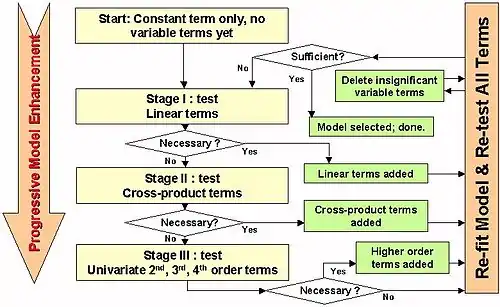
The main approaches are:
- Forward selection, which involves starting with no variables in the model, testing the addition of each variable using a chosen model fit criterion, adding the variable (if any) whose inclusion gives the most statistically significant improvement of the fit, and repeating this process until none improves the model to a statistically significant extent.
- Backward elimination, which involves starting with all candidate variables, testing the deletion of each variable using a chosen model fit criterion, deleting the variable (if any) whose loss gives the most statistically insignificant deterioration of the model fit, and repeating this process until no further variables can be deleted without a statistically insignificant loss of fit.
- Bidirectional elimination, a combination of the above, testing at each step for variables to be included or excluded.
Selection criterion
A widely used algorithm was first proposed by Efroymson (1960).[10] This is an automatic procedure for statistical model selection in cases where there is a large number of potential explanatory variables, and no underlying theory on which to base the model selection. The procedure is used primarily in regression analysis, though the basic approach is applicable in many forms of model selection. This is a variation on forward selection. At each stage in the process, after a new variable is added, a test is made to check if some variables can be deleted without appreciably increasing the residual sum of squares (RSS). The procedure terminates when the measure is (locally) maximized, or when the available improvement falls below some critical value.
One of the main issues with stepwise regression is that it searches a large space of possible models. Hence it is prone to overfitting the data. In other words, stepwise regression will often fit much better in sample than it does on new out-of-sample data. Extreme cases have been noted where models have achieved statistical significance working on random numbers.[11] This problem can be mitigated if the criterion for adding (or deleting) a variable is stiff enough. The key line in the sand is at what can be thought of as the Bonferroni point: namely how significant the best spurious variable should be based on chance alone. On a t-statistic scale, this occurs at about , where p is the number of predictors. Unfortunately, this means that many variables which actually carry signal will not be included. This fence turns out to be the right trade-off between over-fitting and missing signal. If we look at the risk of different cutoffs, then using this bound will be within a 2logp factor of the best possible risk. Any other cutoff will end up having a larger such risk inflation.[12][13]

Model accuracy
A way to test for errors in models created by step-wise regression, is to not rely on the model's F-statistic, significance, or multiple R, but instead assess the model against a set of data that was not used to create the model.[14] This is often done by building a model based on a sample of the dataset available (e.g., 70%) – the “training set” – and use the remainder of the dataset (e.g., 30%) as a validation set to assess the accuracy of the model. Accuracy is then often measured as the actual standard error (SE), MAPE (Mean absolute percentage error), or mean error between the predicted value and the actual value in the hold-out sample.[15] This method is particularly valuable when data are collected in different settings (e.g., different times, social vs. solitary situations) or when models are assumed to be generalizable.
Criticism
Stepwise regression procedures are used in data mining, but are controversial. Several points of criticism have been made.
- The tests themselves are biased, since they are based on the same data.[16][17] Wilkinson and Dallal (1981)[18] computed percentage points of the multiple correlation coefficient by simulation and showed that a final regression obtained by forward selection, said by the F-procedure to be significant at 0.1%, was in fact only significant at 5%.
- When estimating the degrees of freedom, the number of the candidate independent variables from the best fit selected may be smaller than the total number of final model variables, causing the fit to appear better than it is when adjusting the r2 value for the number of degrees of freedom. It is important to consider how many degrees of freedom have been used in the entire model, not just count the number of independent variables in the resulting fit.[19]
- Models that are created may be over-simplifications of the real models of the data.[20]
Such criticisms, based upon limitations of the relationship between a model and procedure and data set used to fit it, are usually addressed by verifying the model on an independent data set, as in the PRESS procedure.
Critics regard the procedure as a paradigmatic example of data dredging, intense computation often being an inadequate substitute for subject area expertise. Additionally, the results of stepwise regression are often used incorrectly without adjusting them for the occurrence of model selection. Especially the practice of fitting the final selected model as if no model selection had taken place and reporting of estimates and confidence intervals as if least-squares theory were valid for them, has been described as a scandal.[7] Widespread incorrect usage and the availability of alternatives such as ensemble learning, leaving all variables in the model, or using expert judgement to identify relevant variables have led to calls to totally avoid stepwise model selection.[5]
See also
References
- Efroymson,M. A. (1960) "Multiple regression analysis," Mathematical Methods for Digital Computers, Ralston A. and Wilf,H. S., (eds.), Wiley, New York.
- Hocking, R. R. (1976) "The Analysis and Selection of Variables in Linear Regression," Biometrics, 32.
- Draper, N. and Smith, H. (1981) Applied Regression Analysis, 2d Edition, New York: John Wiley & Sons, Inc.
- SAS Institute Inc. (1989) SAS/STAT User's Guide, Version 6, Fourth Edition, Volume 2, Cary, NC: SAS Institute Inc.
- Flom, P. L. and Cassell, D. L. (2007) "Stopping stepwise: Why stepwise and similar selection methods are bad, and what you should use," NESUG 2007.
- Harrell, F. E. (2001) "Regression modeling strategies: With applications to linear models, logistic regression, and survival analysis," Springer-Verlag, New York.
- Chatfield, C. (1995) "Model uncertainty, data mining and statistical inference," J. R. Statist. Soc. A 158, Part 3, pp. 419–466.
- Efron, B. and Tibshirani, R. J. (1998) "An introduction to the bootstrap," Chapman & Hall/CRC
- Box–Behnken designs from a handbook on engineering statistics at NIST
- Efroymson, MA (1960) "Multiple regression analysis." In Ralston, A. and Wilf, HS, editors, Mathematical Methods for Digital Computers. Wiley.
- Knecht, WR. (2005). Pilot willingness to take off into marginal weather, Part II: Antecedent overfitting with forward stepwise logistic regression. (Technical Report DOT/FAA/AM-O5/15). Federal Aviation Administration
- Foster, Dean P., & George, Edward I. (1994). The Risk Inflation Criterion for Multiple Regression. Annals of Statistics, 22(4). 1947–1975. doi:10.1214/aos/1176325766
- Donoho, David L., & Johnstone, Jain M. (1994). Ideal spatial adaptation by wavelet shrinkage. Biometrika, 81(3):425–455. doi:10.1093/biomet/81.3.425
- Mark, Jonathan, & Goldberg, Michael A. (2001). Multiple regression analysis and mass assessment: A review of the issues. The Appraisal Journal, Jan., 89–109.
- Mayers, J.H., & Forgy, E.W. (1963). The Development of numerical credit evaluation systems. Journal of the American Statistical Association, 58(303; Sept), 799–806.
- Rencher, A. C., & Pun, F. C. (1980). Inflation of R² in Best Subset Regression. Technometrics, 22, 49–54.
- Copas, J.B. (1983). Regression, prediction and shrinkage. J. Roy. Statist. Soc. Series B, 45, 311–354.
- Wilkinson, L., & Dallal, G.E. (1981). Tests of significance in forward selection regression with an F-to enter stopping rule. Technometrics, 23, 377–380.
- Hurvich, C. M. and C. L. Tsai. 1990. The impact of model selection on inference in linear regression. American Statistician 44: 214–217.
- Roecker, Ellen B. (1991). Prediction error and its estimation for subset—selected models. Technometrics, 33, 459–468.