Regression dilution
Regression dilution, also known as regression attenuation, is the biasing of the regression slope towards zero (the underestimation of its absolute value), caused by errors in the independent variable.
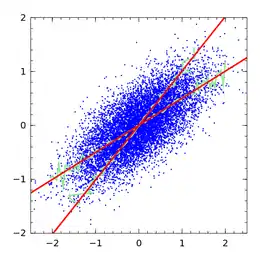
Consider fitting a straight line for the relationship of an outcome variable y to a predictor variable x, and estimating the slope of the line. Statistical variability, measurement error or random noise in the y variable causes uncertainty in the estimated slope, but not bias: on average, the procedure calculates the right slope. However, variability, measurement error or random noise in the x variable causes bias in the estimated slope (as well as imprecision). The greater the variance in the x measurement, the closer the estimated slope must approach zero instead of the true value.
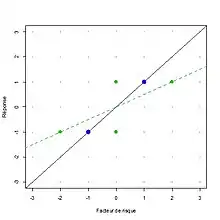
It may seem counter-intuitive that noise in the predictor variable x induces a bias, but noise in the outcome variable y does not. Recall that linear regression is not symmetric: the line of best fit for predicting y from x (the usual linear regression) is not the same as the line of best fit for predicting x from y.[1]
How to correct for regression dilution
The case of a randomly distributed x variable
The case that the x variable arises randomly is known as the structural model or structural relationship. For example, in a medical study patients are recruited as a sample from a population, and their characteristics such as blood pressure may be viewed as arising from a random sample.
Under certain assumptions (typically, normal distribution assumptions) there is a known ratio between the true slope, and the expected estimated slope. Frost and Thompson (2000) review several methods for estimating this ratio and hence correcting the estimated slope.[2] The term regression dilution ratio, although not defined in quite the same way by all authors, is used for this general approach, in which the usual linear regression is fitted, and then a correction applied. The reply to Frost & Thompson by Longford (2001) refers the reader to other methods, expanding the regression model to acknowledge the variability in the x variable, so that no bias arises.[3] Fuller (1987) is one of the standard references for assessing and correcting for regression dilution.[4]
Hughes (1993) shows that the regression dilution ratio methods apply approximately in survival models.[5] Rosner (1992) shows that the ratio methods apply approximately to logistic regression models.[6] Carroll et al. (1995) give more detail on regression dilution in nonlinear models, presenting the regression dilution ratio methods as the simplest case of regression calibration methods, in which additional covariates may also be incorporated.[7]
In general, methods for the structural model require some estimate of the variability of the x variable. This will require repeated measurements of the x variable in the same individuals, either in a sub-study of the main data set, or in a separate data set. Without this information it will not be possible to make a correction.
The case of a fixed x variable
The case that x is fixed, but measured with noise, is known as the functional model or functional relationship. See, for example, Riggs et al. (1978).[8]
Multiple x variables
The case of multiple predictor variables subject to variability (possibly correlated) has been well-studied for linear regression, and for some non-linear regression models.[4][7] Other non-linear models, such as proportional hazards models for survival analysis, have been considered only with a single predictor subject to variability.[5]
Is correction necessary?
In statistical inference based on regression coefficients, yes; in predictive modelling applications, correction is neither necessary nor appropriate. To understand this, consider the measurement error as follows. Let y be the outcome variable, x be the true predictor variable, and w be an approximate observation of x. Frost and Thompson suggest, for example, that x may be the true, long-term blood pressure of a patient, and w may be the blood pressure observed on one particular clinic visit.[2] Regression dilution arises if we are interested in the relationship between y and x, but estimate the relationship between y and w. Because w is measured with variability, the slope of a regression line of y on w is less than the regression line of y on x.
Does this matter? In predictive modelling, no. Standard methods can fit a regression of y on w without bias. There is bias only if we then use the regression of y on w as an approximation to the regression of y on x. In the example, assuming that blood pressure measurements are similarly variable in future patients, our regression line of y on w (observed blood pressure) gives unbiased predictions.
An example of a circumstance in which correction is desired is prediction of change. Suppose the change in x is known under some new circumstance: to estimate the likely change in an outcome variable y, the slope of the regression of y on x is needed, not y on w. This arises in epidemiology. To continue the example in which x denotes blood pressure, perhaps a large clinical trial has provided an estimate of the change in blood pressure under a new treatment; then the possible effect on y, under the new treatment, should be estimated from the slope in the regression of y on x.
Another circumstance is predictive modelling in which future observations are also variable, but not (in the phrase used above) "similarly variable". For example, if the current data set includes blood pressure measured with greater precision than is common in clinical practice. One specific example of this arose when developing a regression equation based on a clinical trial, in which blood pressure was the average of six measurements, for use in clinical practice, where blood pressure is usually a single measurement.[9]
Caveats
All of these results can be shown mathematically, in the case of simple linear regression assuming normal distributions throughout (the framework of Frost & Thompson).
It has been discussed that a poorly executed correction for regression dilution, in particular when performed without checking for the underlying assumptions, may do more damage to an estimate than no correction.[10]
Further reading
Regression dilution was first mentioned, under the name attenuation, by Spearman (1904).[11] Those seeking a readable mathematical treatment might like to start with Frost and Thompson (2000),[2] or see correction for attenuation.
See also
- Correction for attenuation
- Errors-in-variables models
- Quantization (signal processing) – a common source of error in the explanatory or independent variables
References
- Draper, N.R.; Smith, H. (1998). Applied Regression Analysis (3rd ed.). John Wiley. p. 19. ISBN 0-471-17082-8.
- Frost, C. and S. Thompson (2000). "Correcting for regression dilution bias: comparison of methods for a single predictor variable." Journal of the Royal Statistical Society Series A 163: 173–190.
- Longford, N. T. (2001). "Correspondence". Journal of the Royal Statistical Society, Series A. 164: 565. doi:10.1111/1467-985x.00219.
- Fuller, W. A. (1987). Measurement Error Models. New York: Wiley.
- Hughes, M. D. (1993). "Regression dilution in the proportional hazards model". Biometrics. 49: 1056–1066. doi:10.2307/2532247.
- Rosner, B.; Spiegelman, D.; et al. (1992). "Correction of Logistic Regression Relative Risk Estimates and Confidence Intervals for Random Within-Person Measurement Error". American Journal of Epidemiology. 136: 1400–1403. doi:10.1093/oxfordjournals.aje.a116453.
- Carroll, R. J., Ruppert, D., and Stefanski, L. A. (1995). Measurement error in non-linear models. New York, Wiley.
- Riggs, D. S.; Guarnieri, J. A.; et al. (1978). "Fitting straight lines when both variables are subject to error". Life Sciences. 22: 1305–60. doi:10.1016/0024-3205(78)90098-x.
- Stevens, R. J.; Kothari, V.; Adler, A. I.; Stratton, I. M.; Holman, R. R. (2001). "Appendix to "The UKPDS Risk Engine: a model for the risk of coronary heart disease in type 2 diabetes UKPDS 56)". Clinical Science. 101: 671–679. doi:10.1042/cs20000335.
- Davey Smith, G.; Phillips, A. N. (1996). "Inflation in epidemiology: 'The proof and measurement of association between two things' revisited". British Medical Journal. 312 (7047): 1659–1661. doi:10.1136/bmj.312.7047.1659. PMC 2351357. PMID 8664725.
- Spearman, C (1904). "The proof and measurement of association between two things". American Journal of Psychology. 15: 72–101. doi:10.2307/1412159.