PADICAT
PADICAT acronym for Patrimoni Digital de Catalunya, in Catalan; or Digital Heritage of Catalonia, in English, is the Web Archive of Catalonia.[1]
 | |
| URL | http://www.padicat.cat/ |
|---|---|
Created in 2005[2] by the Biblioteca de Catalunya, the public institution responsible for collecting, preserving and distributing the bibliographic heritage, and the digital heritage by extension. Has the technological collaboration of the Center for Scientific and Academic Services of Catalonia, (CESCA) for preserving and giving access to old versions of web pages published on the Internet. The Biblioteca de Catalunya, as the responsible of PADICAT, is member of the International Internet Preservation Consortium (IIPC).[3]
History
PADICAT was born in 2005 following the trend of other national libraries on web archives creation, and as an answer to the publication of the guidelines for the preservation of digital heritage[4] by the UNESCO. There are many web archives running.[5] The most famous began in 1996: the Swedish Kulturarw3;[6] the Australian Pandora,[7] and the most popular repository, Internet Archive.[8]
The analysis of these and other projects, made way to the planning of PADICAT project, following the common trend around the world of a hybrid model of functioning, complementing the regular capture of a whole geographical domain (.cat domain in this case), with selective actions, and expand these coverage to different social events that generate an intense activity in the network (electoral campaigns, for instance) or with thematic packages (museums of Catalonia, Catalan folk-rock on the web, etc.). PADICAT complements all this with users contributions through the recommended webs.
In June 2005, the Biblioteca de Catalunya started the preliminary phase, of planning, in which a projects analysis was performed about existing resources, agents involved in production of web pages of Catalonia and legal issues that determine practices that want to do.
Based on parameters defined by the Biblioteca de Catalunya, on July 21, 2006, began to collect automatically websites likely to be part of the digital heritage of Catalonia. On September 11, 2006, coinciding with celebration of National Day of Catalonia, PADICAT website was opened to the public, with about thirty web pages stored.
The 2006–08 period represents production phase, project plan pilot, PADICAT operation phase: systematic capture of web pages of Catalonia.
The 2009–2011 period, Biblioteca de Catalunya should be in an optimum position, whereby this system -a pioneer in Spain and a benchmark in Europe- operates at full capacity. Furthermore, have reached cooperation agreements with more than 450 institutions of all kinds and has warranted online open access to all collection. On September 11, 2011, coinciding again with the National Day of Catalonia and with the fifth anniversary of its website, PADICAT has opened a new website version to access all deposited contents.
In November 2012, PADICAT has preserved 58,122 webs, 249.609 crawls, 349 million files and 13 TB of disk space. All of them are freely available.[9]
Mission and functioning
Mission and objectives
The mission of PADICAT is to harvest, to process and to provide access to digital heritage of Catalonia born on the Internet. Its objectives are:
- Massive compilation of .cat domain, thanks to the agreement with the Fundació puntCat.[10]
- Systematic archiving of the web site production of Catalan organizations and companies.
- Promote lines of research through themed integration of digital resources related to specific events in Catalan public life, like political campaigns[11] on the Internet, online music phenomenon, or museums on the Internet.
After its birth (2005-2006), growth (2007-2008) and consolidation (2009-2011) phases, since 2012 is wanted to systematize its capacity for growth, with the goal of incorporating 75.700 versions of about 32.000 web sites per year, from:
- A biannual compilation from 30.000 domain .cat resources.
- A biannual compilation from 550 resources from more than 450 organizations with a cooperation agreement.
- A biannual compilation from the resources that users have recommended.
- A daily compilation from a substantial part of 30 online serial publications.
In addition, there are four permanent work areas:
- Defining preservation strategies for the digital heritage born on the Internet. PADICAT provides periodic reports about Catalan web sites; it detects which formats are having illegibility problems; and identifies the most used languages, etc.
- Promoting lines of research by creating monographic collections with involvement of experts from every subject.
- Creating and maintaining a digital serials archive through the systematized capture of digital serials of Internet. Now, it consists of a representative sample about the kind and contents, selected among born digital, without analogical equivalent.
- Cooperating with other web archives, libraries, archives and museums, for giving an efficient answer to challenges on digital preservation and access into its resources.
Software
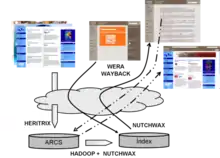
PADICAT is a system based on the implementation of several software that allow web pages to be collected, stored, organized, preserved and permanently accessed. Later to analysis phase and software test was determined that be used Heritrix[12] software, applied in most capture of digital resources projects. This is a software charge to compile web pages as the user sees when surf the Internet and store it in compressed files with ARC or WARC extension. Then, Heritrix software is complemented by NutchWax,[13] or by combination with Hadoop[14] and Wayback,[15] doing an indexing process to compiled information that will permit use these index for localize collection resources from query interfaces: Wera,[16] that permits search from keywords through generated indexes by NutchWax; and Wayback, that lets consult by URL in generated indexes by Hadoop and same Wayback.
Has been used Web Curator Tool[17] software, developed by National Library of New Zealand and British Library, as a document management system that permits allocate metadata to a significant part of collection, in order to integrate, in future, funds of deposit to search in other catalogs, from the Biblioteca de Catalunya or other institutions. Nowadays, websites are being cataloged through CAT,[18] a software expressly developed by CESCA technicians for the project.
Hardware

With regard to hardware that maintains system, there are six nodes HP ProLiant DL360 G4p, charge to collection and indexation tasks of web pages. In charge of results searching and viewing in web interface there is Linux cluster high-availability, with balance features of requests loads and error tolerance if there is a technical disaster of nodes that integrate platform. NetApp FAS3170 cabin presents 19TB of disk capacity via NFS to these nodes.
Nodes are connected with fibre to a Storage Area Network (SAN) and is complemented with saving system of data backup robot.
Is expected to include the deposited contents in PADICAT to COFRE[19] (COnservem per al Futur Recursos Electrònics), a high security preservation system created for the Biblioteca de Catalunya
References
- Official website
- Biblioteca de Catalunya (2005), Memòria del plantejament del projecte PADICAT (Patrimoni Digital de Catalunya), Barcelona: Biblioteca de Catalunya, retrieved 2012-11-22
- International Internet Preservation Consortium
- National Library of Australia (2003), Guidelines for the preservation of digital heritage (PDF), Canberra: UNESCO, retrieved 2012-11-22
- Llueca, Ciro (2005), Webs sempre accessibles : les biblioteques nacionals i els dipòsits digitals nacionals, BiD: textos universitaris de biblioteconomia i documentació, retrieved 2012-11-20
- Kulturarw3
- Pandora
- Internet Archive
- PADICAT
- Cooperation agreement between the Biblioteca de Catalunya and fundació puntCAT, for the preservation of web pages, has been signed
- Llueca, Ciro; Cócera, Daniel; Torres, Natàlia; et al. (2012), A ritmo de tweet: archivando elecciones 2.0 (PDF), El profesional de la información, retrieved 2012-11-21
- Heritrix
- NutcWax
- Hadoop
- Wayback
- Wera
- Web Curator Tool
- Llueca, Ciro; Cócera, Daniel; Torresa, Natàlia; et al. (2010), CAT (Curator Archiving Tool): improving access to web archives = CAT (Curator Archiving Tool): millorant l'accés als arxius web = CAT (Curator Archiving Tool): mejorando el acceso a los archivos web (PDF), retrieved 2012-11-21
- Serra, Eugènia; Pérez, Karibel; Llueca, Ciro (2012), "La Biblioteca de Catalunya i l'accés al patrimoni digital", Métodos de Informacion, MEI, 2 (2): 5–20, doi:10.5557/IIMEI2-N2-005020, retrieved 2012-11-21