Memory ordering
Memory ordering describes the order of accesses to computer memory by a CPU. The term can refer either to the memory ordering generated by the compiler during compile time, or to the memory ordering generated by a CPU during runtime.
In modern microprocessors, memory ordering characterizes the CPUs ability to reorder memory operations – it is a type of out-of-order execution. Memory reordering can be used to fully utilize the bus-bandwidth of different types of memory such as caches and memory banks.
On most modern uniprocessors memory operations are not executed in the order specified by the program code. In single threaded programs all operations appear to have been executed in the order specified, with all out-of-order execution hidden to the programmer – however in multi-threaded environments (or when interfacing with other hardware via memory buses) this can lead to problems. To avoid problems, memory barriers can be used in these cases.
Compile-time memory ordering
Most programming languages have some notion of a thread of execution which executes statements in a defined order. Traditional compilers translate high-level expressions to a sequence of low-level instructions relative to a program counter at the underlying machine level.
Execution effects are visible at two levels: within the program code at a high level, and at the machine level as viewed by other threads or processing elements in concurrent programming, or during debugging when using a hardware debugging aid with access to the machine state (some support for this is often built directly into the CPU or microcontroller as functionally independent circuitry apart from the execution core which continues to operate even when the core itself is halted for static inspection of its execution state). Compile-time memory order concerns itself with the former, and does not concern itself with these other views.
Program-order effects of expression evaluation
During compilation, hardware instructions are often generated at a finer granularity than specified in the high-level code. The primary observable effect in a procedural programming is assignment of a new value to a named variable.
sum = a + b + c; print(sum);
The print statement follows the statement which assigns to the variable sum, and thus when the print statement references the computed variable sum it references this result as an observable effect of the prior execution sequence. As defined by the rules of program sequence, when the print function call references sum, the value of sum must be that of the most recently executed assignment to the variable sum (in this case the immediately previous statement).
At the machine level, few machines can add three numbers together in a single instruction, and so the compiler will have to translate this expression into two addition operations. If the semantics of the program language restrict the compiler into translating the expression in left-to-right order (for example), then the generated code will look as if the programmer had written the following statements in the original program:
sum = a + b; sum = sum + c;
If the compiler is permitted to exploit the associative property of addition, it might instead generate:
sum = b + c; sum = a + sum;
If the compiler is also permitted to exploit the commutative property of addition, it might instead generate:
sum = a + c; sum = sum + b;
Note that the integer data type in most programming languages only follows the algebra for the mathematics integers in the absence of integer overflow and that floating-point arithmetic on the floating point data type available in most programming languages is not commutative in rounding effects, making effects of the order of expression visible in small differences of the computed result (small initial differences may however cascade into arbitrarily large differences over a longer computation).
If the programmer is concerned about integer overflow or rounding effects in floating point, the same program may be coded at the original high level as follows:
sum = a + b; sum = sum + c;
Program-order effects involving function calls
Many languages treat the statement boundary as a sequence point, forcing all effects of one statement to be complete before the next statement is executed. This will force the compiler to generate code corresponding to the statement order expressed. Statements are, however, often more complicated, and may contain internal function calls.
sum = f(a) + g(b) + h(c);
At the machine level, calling a function usually involves setting up a stack frame for the function call, which involves many reads and writes to machine memory. In most compiled languages, the compiler is free to order the function calls f, g, and h as it finds convenient, resulting in large-scale changes of program memory order. In a functional programming language, function calls are forbidden from having side effects on the visible program state (other than its return value) and the difference in machine memory order due to function call ordering will be inconsequential to program semantics. In procedural languages, the functions called might have side-effects, such as performing an I/O operation, or updating a variable in global program scope, both of which produce visible effects with the program model.
Again, a programmer concerned with these effects can become more pedantic in expressing the original source program:
sum = f(a); sum = sum + g(b); sum = sum + h(c);
In programming languages where the statement boundary is defined as a sequence point, the function calls f, g, and h must now execute in that precise order.
Program-order effects involving pointer expressions
Now consider the same summation expressed with pointer indirection, in a language such as C/C++ which supports pointers:
sum = *a + *b + *c;
Evaluating the expression *x is termed "dereferencing" a pointer and involves reading from memory at a location specified by the current value of x. The effects of reading from a pointer are determined by architecture's memory model. When reading from standard program storage, there are no side-effects due to the order of memory read operations. In embedded system programming, it is very common to have memory-mapped I/O where reads and writes to memory trigger I/O operations, or changes to the processor's operational mode, which are highly visible side effects. For the above example, assume for now that the pointers are pointing to regular program memory, without these side-effects. The compiler is free to reorder these reads in program order as it sees fit, and there will be no program-visible side effects.
What if assigned value is also pointer indirected?
*sum = *a + *b + *c;
Here the language definition is unlikely to allow the compiler to break this apart as follows:
// as rewritten by the compiler // generally forbidden *sum = *a + *b; *sum = *sum + *c;
This would not be viewed as efficient in most instances, and pointer writes have potential side-effects on visible machine state. Since the compiler is not allowed this particular splitting transformation, the only write to the memory location of sum must logically follow the three pointer reads in the value expression.
Suppose, however, that the programmer is concerned about the visible semantics of integer overflow and breaks the statement apart as the program level as follows:
// as directly authored by the programmer // with aliasing concerns *sum = *a + *b; *sum = *sum + *c;
The first statement encodes two memory reads, which must precede (in either order) the first write to *sum. The second statement encodes two memory reads (in either order) which must precede the second update of *sum. This guarantees the order of the two addition operations, but potentially introduces a new problem of address aliasing: any of these pointers could potentially refer to the same memory location.
For example, let's assume in this example that *c and *sum are aliased to the same memory location, and rewrite both versions of the program with *sum standing in for both.
*sum = *a + *b + *sum;
There are no problems here. The original value of what we originally wrote as *c is lost upon assignment to *sum, and so is the original value of *sum but this was overwritten in the first place and it's of no special concern.
// what the program becomes with *c and *sum aliased *sum = *a + *b; *sum = *sum + *sum;
Here the original value of *sum is overwritten before its first access, and instead we obtain the algebraic equivalent of:
// algebraic equivalent of the aliased case above *sum = (*a + *b) + (*a + *b);
which assigns an entirely different value into *sum due to the statement rearrangement.
Because of possible aliasing effects, pointer expressions are difficult to rearrange without risking visible program effects. In the common case, there might not be any aliasing in effect, so the code appears to run normally as before. But in the edge case where aliasing is present, severe program errors can result. Even if these edge cases are entirely absent in normal execution, it opens the door for a malicious adversary to contrive an input where aliasing exists, potentially leading to a computer security exploit.
A safe reordering of the previous program is as follows:
// declare a temporary local variable 'temp' of suitable type temp = *a + *b; *sum = temp + *c;
Finally consider the indirect case with added function calls:
*sum = f(*a) + g(*b);
The compiler may choose to evaluate *a and *b before either function call, it may defer the evaluation of *b until after the function call f or it may defer the evaluation of *a until after the function call g. If the function f and g are free from program visible side-effects, all three choices will produce program with the same visible program effects. If the implementation of f or g contain the side-effect of any pointer write subject to aliasing with pointers a or b, the three choices are liable to produce different visible program effects.
Memory order in language specification
In general, compiled languages are not detailed enough in their specification for the compiler to determine formally at compile time which pointers are potentially aliased and which are not. The safest course of action is for the compiler to assume that all pointers are potentially aliased at all times. This level of conservative pessimism tends to produce dreadful performance as compared to the optimistic assumption that no aliasing exists, ever.
As a result, many high-level compiled languages, such as C/C++, have evolved to have intricate and sophisticated semantic specifications about where the compiler is permitted to make optimistic assumptions in code reordering in pursuit of the highest possible performance, and where the compiler is required to make pessimistic assumptions in code reordering to avoid semantic hazards.
By far the largest class of side effects in a modern procedural language involve memory write operations, so rules around memory ordering are a dominant component in the definition of program order semantics. The reordering of the functions calls above might appear to be a different consideration, but this usually devolves into concerns about memory effects internal to the called functions interacting with memory operations in the expression which generates the function call.
Optimization under as-if
Modern compilers sometimes take this a step further by means of an as-if rule, in which any reordering is permitted (even across statements) if no effect on the visible program semantics results. Under this rule, the order of operations in the translated code can vary wildly from the specified program order. If the compiler is permitted to make optimistic assumptions about distinct pointer expressions having no alias overlap in a case where such aliasing actually exists (this would normally be classified as an ill-formed program exhibiting undefined behavior), the adverse results of an aggressive code-optimization transformation are impossible to guess prior to code execution or direct code inspection. The realm of undefined behavior has nearly limitless manifestations.
It is the responsibility of the programmer to consult the language specification to avoid writing ill-formed programs where the semantics are potentially changed as a result of any legal compiler optimization. Fortran traditionally places a high burden on the programmer to be aware of these issues, with the systems programming languages C and C++ not far behind.
Some high-level languages eliminate pointer constructions altogether, as this level of alertness and attention to detail is considered too high to reliably maintain even among professional programmers.
A complete grasp of memory order semantics is considered to be an arcane specialization even among the subpopulation of professional systems programmers who are typically best informed in this subject area. Most programmers settle for an adequate working grasp of these issues within the normal domain of their programming expertise. At the extreme end of specialization in memory order semantics are the programmers who author software frameworks in support of concurrent computing models.
Aliasing of local variables
Note that local variables can not be assumed to be free of aliasing if a pointer to such a variable escapes into the wild:
sum = f(&a) + g(a);
There is no telling what the function f might have done with the supplied pointer to a, including leaving a copy around in global state which the function g later accesses. In the simplest case, f writes a new value to the variable a, making this expression ill-defined in order of execution. f can be conspicuously prevented from doing this by applying a const qualifier to the declaration of its pointer argument, rendering the expression well defined. Thus the modern culture of C/C++ has become somewhat obsessive about supplying const qualifiers to function argument declarations in all viable cases.
C and C++ permit the internals of f to type cast the constness attribute away as a dangerous expedient. If f does this in a way that can break the expression above, it should not be declaring the pointer argument type as const in the first place.
Other high-level languages tilt toward such a declaration attribute amounting to a strong guarantee with no loop-holes to violate this guarantee provided within the language itself; all bets are off on this language guarantee if your application links a library written in a different programming language (though this is considered to be egregiously bad design).
Compile-time memory barrier implementation
These barriers prevent a compiler from reordering instructions during compile time – they do not prevent reordering by CPU during runtime.
- The GNU inline assembler statement
asm volatile("" ::: "memory");
or even
__asm__ __volatile__ ("" ::: "memory");
forbids GCC compiler to reorder read and write commands around it.[1]
- The C11/C++11 function
atomic_signal_fence(memory_order_acq_rel);
forbids the compiler to reorder read and write commands around it.[2]
- Intel ICC compiler uses "full compiler fence"
__memory_barrier()
- Microsoft Visual C++ Compiler:[5]
_ReadWriteBarrier()
Combined barriers
In many programming languages different types of barriers can be combined with other operations (like load, store, atomic increment, atomic compare and swap), so no extra memory barrier is needed before or after it (or both). Depending on a CPU architecture being targeted these language constructs will translate to either special instructions, to multiple instructions (i.e. barrier and load), or to normal instruction, depending on hardware memory ordering guarantees.
Runtime memory ordering
In symmetric multiprocessing (SMP) microprocessor systems
There are several memory-consistency models for SMP systems:
- Sequential consistency (all reads and all writes are in-order)
- Relaxed consistency (some types of reordering are allowed)
- Loads can be reordered after loads (for better working of cache coherency, better scaling)
- Loads can be reordered after stores
- Stores can be reordered after stores
- Stores can be reordered after loads
- Weak consistency (reads and writes are arbitrarily reordered, limited only by explicit memory barriers)
On some CPUs
- Atomic operations can be reordered with loads and stores.[6]
- There can be incoherent instruction cache pipeline, which prevents self-modifying code from being executed without special instruction cache flush/reload instructions.
- Dependent loads can be reordered (this is unique for Alpha). If the processor fetches a pointer to some data after this reordering, it might not fetch the data itself but use stale data which it has already cached and not yet invalidated. Allowing this relaxation makes cache hardware simpler and faster but leads to the requirement of memory barriers for readers and writers.[7] On Alpha hardware (like multiprocessor Alpha 21264 systems) cache line invalidations sent to other processors are processed in lazy fashion by default, unless requested explicitly to be processed between dependent loads. The Alpha architecture specification also allows other forms of dependent loads reordering, for example using speculative data reads ahead of knowing the real pointer to be dereferenced.
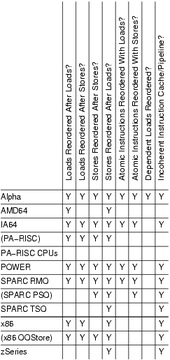
| Type | Alpha | ARMv7 | MIPS | RISC-V | PA-RISC | POWER | SPARC | x86 [lower-alpha 1] | AMD64 | IA-64 | z/Architecture | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WMO | TSO | RMO | PSO | TSO | ||||||||||
| Loads can be reordered after loads | Y | Y | depend on implementation | Y | Y | Y | Y | Y | ||||||
| Loads can be reordered after stores | Y | Y | Y | Y | Y | Y | Y | |||||||
| Stores can be reordered after stores | Y | Y | Y | Y | Y | Y | Y | Y | ||||||
| Stores can be reordered after loads | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | |
| Atomic can be reordered with loads | Y | Y | Y | Y | Y | Y | ||||||||
| Atomic can be reordered with stores | Y | Y | Y | Y | Y | Y | Y | |||||||
| Dependent loads can be reordered | Y | |||||||||||||
| Incoherent instruction cache pipeline | Y | Y | Y | Y | Y | Y | Y | Y | Y | |||||
- This column indicates the behaviour of the vast majority of x86 processors. Some rare specialised x86 processors (IDT WinChip manufactured around 1998) may have weaker 'oostore' memory ordering.[10]
RISC-V memory ordering models:
- WMO
- Weak memory order (default)
- TSO
- Total store order (only supported with the Ztso extension)
SPARC memory ordering modes:
- TSO
- Total store order (default)
- RMO
- Relaxed-memory order (not supported on recent CPUs)
- PSO
- Partial store order (not supported on recent CPUs)
Hardware memory barrier implementation
Many architectures with SMP support have special hardware instruction for flushing reads and writes during runtime.
lfence (asm), void _mm_lfence(void) sfence (asm), void _mm_sfence(void)[11] mfence (asm), void _mm_mfence(void)[12]
sync (asm)
sync (asm)
mf (asm)
dcs (asm)
dmb (asm) dsb (asm) isb (asm)
Compiler support for hardware memory barriers
Some compilers support builtins that emit hardware memory barrier instructions:
- GCC,[14] version 4.4.0 and later,[15] has
__sync_synchronize. - Since C11 and C++11 an
atomic_thread_fence()command was added. - The Microsoft Visual C++ compiler[16] has
MemoryBarrier(). - Sun Studio Compiler Suite[17] has
__machine_r_barrier,__machine_w_barrierand__machine_rw_barrier.
See also
References
- GCC compiler-gcc.h Archived 2011-07-24 at the Wayback Machine
- ECC compiler-intel.h Archived 2011-07-24 at the Wayback Machine
- Intel(R) C++ Compiler Intrinsics Reference
Creates a barrier across which the compiler will not schedule any data access instruction. The compiler may allocate local data in registers across a memory barrier, but not global data.
- Visual C++ Language Reference _ReadWriteBarrier
- Victor Alessandrini, 2015. Shared Memory Application Programming: Concepts and Strategies in Multicore Application Programming. Elsevier Science. p. 176. ISBN 978-0-12-803820-8.
- Reordering on an Alpha processor by Kourosh Gharachorloo
- Memory Ordering in Modern Microprocessors by Paul McKenney
- Memory Barriers: a Hardware View for Software Hackers, Figure 5 on Page 16
- Table 1. Summary of Memory Ordering, from "Memory Ordering in Modern Microprocessors, Part I"
- SFENCE — Store Fence
- MFENCE — Memory Fence
- Data Memory Barrier, Data Synchronization Barrier, and Instruction Synchronization Barrier.
- Atomic Builtins
- "36793 – x86-64 does not get __sync_synchronize right".
- MemoryBarrier macro
- Handling Memory Ordering in Multithreaded Applications with Oracle Solaris Studio 12 Update 2: Part 2, Memory Barriers and Memory Fence
{kind=link}
Further reading
- Computer Architecture — A quantitative approach. 4th edition. J Hennessy, D Patterson, 2007. Chapter 4.6
- Sarita V. Adve, Kourosh Gharachorloo, Shared Memory Consistency Models: A Tutorial
- Intel 64 Architecture Memory Ordering White Paper
- Memory ordering in Modern Microprocessors part 1
- Memory ordering in Modern Microprocessors part 2
- IA (Intel Architecture) Memory Ordering on YouTube - Google Tech Talk