Information gain in decision trees
In information theory and machine learning, information gain is a synonym for Kullback–Leibler divergence; the amount of information gained about a random variable or signal from observing another random variable. However, in the context of decision trees, the term is sometimes used synonymously with mutual information, which is the conditional expected value of the Kullback–Leibler divergence of the univariate probability distribution of one variable from the conditional distribution of this variable given the other one.
The information gain of a random variable X obtained from an observation of a random variable A taking value is defined


the Kullback–Leibler divergence of the prior distribution for x from the posterior distribution for x given a.


The expected value of the information gain is the mutual information of X and A – i.e. the reduction in the entropy of X achieved by learning the state of the random variable A.

In machine learning, this concept can be used to define a preferred sequence of attributes to investigate to most rapidly narrow down the state of X. Such a sequence (which depends on the outcome of the investigation of previous attributes at each stage) is called a decision tree and applied in the area of machine learning known as decision tree learning. Usually an attribute with high mutual information should be preferred to other attributes.
General definition
In general terms, the expected information gain is the change in information entropy Η from a prior state to a state that takes some information as given:

where is the conditional entropy of given the value of attribute .



Formal definition
Let denote a set of training examples, each of the form where is the value of the attribute or feature of example and y is the corresponding class label. The information gain for an attribute is defined in terms of Shannon entropy as follows. For a value taken by attribute , let







be defined as the set of training inputs of for which attribute is equal to . Then the information gain of for attribute is the difference between the a priori Shannon entropy of the training set and the conditional entropy .



The mutual information is equal to the total entropy for an attribute if for each of the attribute values a unique classification can be made for the result attribute. In this case, the relative entropies subtracted from the total entropy are 0. In particular, the values defines a partition of the training set data into mutually exclusive and all-inclusive subsets, inducing a categorical probability distribution on the values of attribute . The distribution is given . In this representation, the information gain of given can be defined as the difference between the unconditional Shannon entropy of and the expected entropy of conditioned on , where the expectation value is taken with respect to the induced distribution on the values of .





Drawbacks
Although information gain is usually a good measure for deciding the relevance of an attribute, it is not perfect. A notable problem occurs when information gain is applied to attributes that can take on a large number of distinct values. For example, suppose that one is building a decision tree for some data describing the customers of a business. Information gain is often used to decide which of the attributes are the most relevant, so they can be tested near the root of the tree. One of the input attributes might be the customer's credit card number. This attribute has a high mutual information, because it uniquely identifies each customer, but we do not want to include it in the decision tree: deciding how to treat a customer based on their credit card number is unlikely to generalize to customers we haven't seen before (overfitting).
To counter this problem, Ross Quinlan proposed to instead choose the attribute with highest information gain ratio from among the attributes whose information gain is average or higher.[1] This biases the decision tree against considering attributes with a large number of distinct values, while not giving an unfair advantage to attributes with very low information value, as the information value is higher or equal to the information gain.[2]
Example
Let’s use this table as a dataset and use information gain to classify if a patient is sick with a disease. Patients classified as True(T) are sick and patients classified as False(F) are not sick. We are currently at the root node of the tree and must consider all possible splits using the data.
| Patient | Symptom A | Symptom B | Symptom C | Classification |
|---|---|---|---|---|
| 1 | T | T | T | F |
| 2 | T | F | T | T |
| 3 | F | F | T | T |
| 4 | F | T | T | F |
| 5 | F | T | F | T |
Candidate Splits are determined by looking at each variable that makes up a patient and what its states can be. In this example all symptoms can either be True(T) or False(F).
| Split | Child Nodes |
|---|---|
| 1 | Symptom A = T, Symptom A = F |
| 2 | Symptom B = T, Symptom B = F |
| 3 | Symptom C = T, Symptom C = F |
Now for split #1, we determine the entropy before the split which is found using the classification of each patient.

The conditional entropy of split #1 is determined by finding the entropy of each state of symptom A and combining them.

Information gain can then be determined by finding the difference in the prior entropy and the conditional entropy.

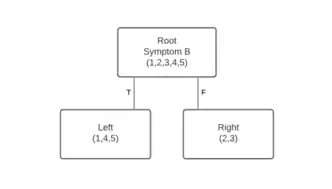
These steps are repeated for all candidate splits to get their information gain. All candidate splits for a node use the same value for .

| Split | Information Gain |
|---|---|
| 1 | 0.020 |
| 2 | 0.419 |
| 3 | 0.171 |
Candidate Split #2 has the highest information gain, so it will be the most favorable split for the root node. Depending on the confidence of the child nodes classifications, information gain can be applied to the child nodes but cannot use the same candidate split.
See also
- Information gain more broadly
- Decision tree learning
- Information content, the starting point of information theory and the basis of Shannon entropy
- Information gain ratio
- ID3 algorithm
- Surprisal analysis
References
- Quinlan, J. Ross (1986). "Induction of Decision Trees". Machine Learning. 1 (1): 81–106. doi:10.1007/BF00116251.
- Milman, Oren (August 6, 2018). "What is the range of information gain ratio?". Stack Exchange. Retrieved 2018-10-09.
Further reading
- Mitchell, Tom M. (1997). Machine Learning. The Mc-Graw-Hill Companies, Inc. ISBN 978-0070428072.