Geospatial predictive modeling
Geospatial predictive modeling is conceptually rooted in the principle that the occurrences of events being modeled are limited in distribution. Occurrences of events are neither uniform nor random in distribution – there are spatial environment factors (infrastructure, sociocultural, topographic, etc.) that constrain and influence where the locations of events occur. Geospatial predictive modeling attempts to describe those constraints and influences by spatially correlating occurrences of historical geospatial locations with environmental factors that represent those constraints and influences. Geospatial predictive modeling is a process for analyzing events through a geographic filter in order to make statements of likelihood for event occurrence or emergence.[1] [2]
Predictive models
There are two broad types of geospatial predictive models: deductive and inductive.
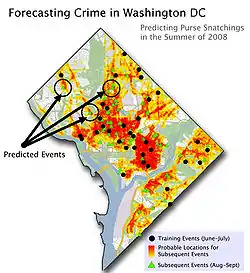
The risk assessment was generated using an inductive predictive modeling tool.
Deductive method
The deductive method relies on qualitative data or a subject matter expert (SME) to describe the relationship between event occurrences and factors that describe the environment. As a result, the deductive process generally will rely on more subjective information. This means that the modeler could potentially be limiting the model by only inputting a number of factors that the human brain can comprehend.
An example of a deductive model is as follows: Sets of events are typically found …
- Between 100 and 700 meters from airports.
- In the grassland land cover category.
- At elevations between 1000 and 1500 meters.
In this deductive model, high suitability locations for the set of events are constrained and influenced by non-empirically calculated spatial ranges for airports, land cover, and elevation: lower suitability areas would be everywhere else. The accuracy and detail of the deductive model is limited by the depth of qualitative data inputs to the model.
Inductive method
The inductive method relies on the empirically-calculated spatial relationship between historical or known event occurrence locations and factors that make up the environment (infrastructure, socio-culture, topographic, etc.). Each event occurrence is plotted in geographic space and a quantitative relationship is defined between the event occurrence and the factors that make up the environment. The advantage of this method is that software can be developed to empirically discover – harnessing the speed of computers, which is crucial when hundreds of factors are involved – both known and unknown correlations between factors and events. Those quantitative relationship values are then processed by a statistical function to find spatial patterns that define high and low suitability areas for event occurrence.
See also
- Predictive Analysis
- Predictive modelling
- Suitability analysis
References
-
- Gary P. Beauvais, Douglas A. Keinath, Pilar Hernandez, Larry Master, Rob Thurston. Element Distribution Modeling: A Primer (Version 2) Archived 2016-03-03 at the Wayback Machine, Natureserve, Arlington, Virginia, June 1, 2006, last referenced December 29, 2009
-
- Donald Brown, Jason Dalton, and Heidi Hoyle. Spatial forecast methods for terrorist events in urban environments, In Proceedings of the Second NSF/NIJ Symposium on Intelligence and Security Informatics, Lecture Notes in Computer Science, pages 426–435, Tucson, Arizona, Springer-Verlag Heidelberg, June 2004.