Fujisaki model
The Fujisaki model is a superpositional model for representing F0 contour of speech.
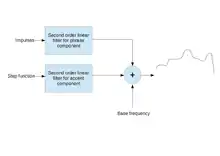
An F0 contour is obtained by adding the phrase and accent components to the base frequency
According to the model, F0 contour is generated as a result of the superposition of the outputs of two second order linear filters with a base frequency value. The second order linear filters are for generating the phrase and accent components of speech. The base frequency is the minimum frequency value of the speaker. In other words, F0 contour is obtained by adding base frequency, phrase components and accent components. The model was proposed by Hiroya Fujisaki.
where



References
- An Introduction to Text-to-Speech Synthesis[1]
- Keikichi Hirose; Hiroya Fujisaki; Mikio Yamaguchi (1984). "Synthesis by rule of voice fundamental frequency contours of spoken Japanese from linguistic information". IEEE.
- Dutoit, Thierry (2001). An Introduction to Text-to-Speech Synthesis. Kluwer Academic Publishers. ISBN 1-4020-0369-2.
This article is issued from Wikipedia. The text is licensed under Creative Commons - Attribution - Sharealike. Additional terms may apply for the media files.