Ezh
Ezh (Ʒ ʒ) /ˈɛʒ/, also called the "tailed z", is a letter whose lower case form is used in the International Phonetic Alphabet (IPA), representing the voiced postalveolar fricative consonant. For example, the pronunciation of "si" in vision /ˈvɪʒən/ and precision /prɪˈsɪʒən/, or the "s" in treasure /ˈtrɛʒər/. See also Ž, the Persian alphabet letter ژ and the Cyrillic ж.
| Ʒ | |
|---|---|
| Ʒ ʒ | |
| (See below, Typography) | |
 | |
| Usage | |
| Writing system | Latin script |
| Type | Alphabetic and Logographic |
| Language of origin | Latin language |
| Phonetic usage | [ʒ] [d͡z] [d͡ʒ] [d͡ʑ] /ˈɛʒ/ |
| Unicode codepoint | U+01B7, U+0292 |
| History | |
| Development | |
| Time period | 1847 to present |
| Descendants | • Ƹ • Ǯ |
| Sisters | Ž З Ѕ Ԑ Ԇ Ҙ ꙅ ז ز ܙ ژ ࠆ ዘ 𐎇 Զ զ Ꮓ Ꮛ Ꮸ ડ ઢ ज़ |
| Transliteration equivalents | zh, ž |
| Variations | (See below, Typography) |
| Other | |
| Other letters commonly used with | z(x), zh, ž |
| Ʒ ʒ |
| Ʒ ʒ |
Ezh is also used as a letter in some orthographies of Laz and Skolt Sami, both by itself, and with a caron (Ǯ ǯ). In Laz, these represent voiceless alveolar affricate /ts/ and its ejective counterpart /tsʼ/, respectively. In Skolt Sami they respectively denote partially voiced alveolar and post-alveolar affricates, broadly represented /dz/ and /dʒ/. It also appears in the orthography of some African languages, for example in the Aja language of Benin and the Dagbani language of Ghana, where the uppercase variant looks like a reflected sigma (Σ).
Origin
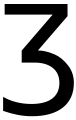
As a phonetic symbol, it originates with Isaac Pitman's English Phonotypic Alphabet in 1847, as a z with an added hook. The symbol is based on medieval cursive forms of Latin z, evolving into the blackletter z letter. In Unicode, however, the blackletter z ("tailed z" , German geschwänztes Z) is considered a glyph variant of z, and not an ezh.
In contexts where "tailed z" is used in contrast to tail-less z, notably in standard transcription of Middle High German, Unicode ʒ is sometimes used, strictly speaking incorrectly. Unicode offers ȥ "z with hook" as a grapheme for Middle High German coronal fricative instead.
Similar shapes
Relation to yogh
In Unicode 1.0, the character was unified with the unrelated character yogh (Ȝ ȝ), which was not correctly added to Unicode until Unicode 3.0. Historically, ezh is derived from Latin z, but yogh is derived from Latin g by way of insular G (and incidentally giving rise to the English mispronunciation of the Scottish surname [and business] Menzies as [ˈmenziz] instead of [ˈmɪŋɪs]). The characters look very similar and do not appear alongside each other in any alphabet. To differentiate between the two more clearly, the Oxford University Press and the Early English Text Society extend the uppermost tip of the 'yogh' into a little curvature upward.
Relation to the digit three
The ezh looks similar to the common form of the figure three (3). To differentiate between the two characters, Ezh includes the sharp zigzag of the letter z, while the number is usually curved. This still remains a problem though, as some type fonts (found on clock faces among other things) use a figure for "3" identical in shape to an ezh. In the Cyrillic script handwritings, the digit 3 is written as an Ezh to distinguish it from the letter Ze.
Similarity to hiragana ro

Ezh looks similar to ろ, the Japanese hiragana letter for the mora "ro". However, the central corner of ろ points out further away to the left than that of ezh.
Vague ties to the Cyrillic 'Ze'

The Cyrillic letter Ze, written as З (capitalized) or з (Lower Case), has a similar body to Ezh. As customary, the Cyrillic script has a stiffer structure, but both letters have common roots in historical cursive forms of ‘Z’, taken from the Greek letter Zeta.
The pronunciations of Latin Ezh and Cyrillic Ze, however, are different phonemes: while /Ӡ/ stands for the s in the word vision, Russian Ze (З) stands for z as in zebra. For the /Ӡ/ phoneme, Cyrillic uses 'Zhe (Ж)'.
Older Russian typewriters, often to save space, sometimes used З (Ze) to write the numeral form of 3.
Usage
Language orthographies
In the International Phonetic Alphabet (IPA) it represents the voiced postalveolar fricative consonant. For example: vision /ˈvɪʒən/. It is pronounced as the "s" in "treasure" or the "si" in the word "precision".
It is used with that value in Uropi.
It is used in the "International Standard" orthography, as devised by Marcel Courthiade for Romani.
It was also used in an obsolete Latin alphabet for writing Komi, where it represented [d͡ʑ] (similar to English j). In the modern Cyrillic alphabet, this sound is written as дз.
Also during Latinisation in the USSR was used in the project of Unified Northern Alphabet and other alphabets of the people of the Soviet Union in the 20-30s years.
Ezh as an abbreviation for dram
In Unicode, a standard designed to allow symbols from all writing systems to be represented and manipulated by computers, the ezh (alternatively ℨ) is used as the symbol to represent the abbreviation for dram, an apothecaries' system unit of mass.
Encoding and ligatures
The Unicode code points are U+01B7 for Ʒ and U+0292 for ʒ.
The IPA historically allowed for ezh to be ligatured to other letters; some of these ligatures have been added to the Unicode standard.
- Dezh (ʤ) ligatures ezh with the letter D (U+02A4).
- Lezh (ɮ) ligatures ezh with the letter L (U+026E).
- Tezh (ꜩ) (uppercase form Ꜩ) ligatures ezh with the letter T (U+A728 for Ꜩ and U+A729 for ꜩ).
Related obsolete IPA characters include U+01BA ƺ LATIN SMALL LETTER EZH WITH TAIL and U+0293 ʓ LATIN SMALL LETTER EZH WITH CURL.
U+1DBE ᶾ MODIFIER LETTER SMALL EZH and U+1D9A ᶚ LATIN SMALL LETTER EZH WITH RETROFLEX HOOK are also used for phonetic transcription.[1]
U+1D23 ᴣ LATIN LETTER SMALL CAPITAL EZH is used in the Uralic Phonetic Alphabet.[2]
Typing character
For Mac: Option⌥ + :, followed by Shift+Z or Z respectively.
See also
- Unified Northern Alphabet
- Reversed Ezh (Ƹ ƹ)
- Abkhazian Dze (Ӡ ӡ)
- Cyrillic Ze (З з)
References
- Constable, Peter (2004-04-19). "L2/04-132 Proposal to add additional phonetic characters to the UCS" (PDF).
- Everson, Michael; et al. (2002-03-20). "L2/02-141: Uralic Phonetic Alphabet characters for the UCS" (PDF).