Architecture of Btrieve
Btrieve is a database developed by Pervasive Software. The architecture of Btrieve has been designed with record management in mind. This means that Btrieve only deals with the underlying record creation, data retrieval, record updating and data deletion primitives. Together with the MicroKernel Database Engine it uses ISAM, Indexed Sequential Access Method, as its underlying storage mechanism.
Btrieve is essentially a database that uses keys and indexes to organise data. However, the file structure itself is largely built around smaller units of data, called "pages" in Btrieve. Though the structure has changed over the various versions of Btrieve, the file structure still revolves around a File Control Record (FCR) — which defines the configuration of pages — and pages in the Btrieve file that contain data. Historically, Btrieve used "physical pages", or pages that were located at fixed positions in the file. Beginning with version 6.0 "logical pages" started to be used, which were mapped to page allocation tables (PATs) — this allowed Btrieve to change their record update technique from what was later known as "pre-image paging" to a technique called "shadow-paging".
Btrieve is committed to backward compatibility, as versions of Btrieve until version 6.15 use a standard file format and, until Btrieve 6.0 was released, were completely backwards compatible. Btrieve 6.0 introduced new features and had to break compatibility with older versions of the software to implement more advanced features. The API likewise remained backwards compatible, with only one feature (split files to separate media) being dropped. At one point, Btrieve's former CEO Ron Harris stated that "The version 1.0 API is still supported in version 6.15, and we're going to keep it forever!" (Kyle, pg 11).
Database terminology
Pervasive initially used the term "navigational database" to describe Btrieve, but later changed this to "transactional database". The use of the term navigational database was unusual because a navigational database uses "pointers" and "paths" to navigate among data records, and these pointers are contained in the record itself; ISAM, which is the fundamental structure of Btrieve, uses a secondary index table to store these pointers to decrease search times. Thus, the two types of database are different, and may or may not explain why Pervasive started using different terminology for classifying their database. (Note: This is not strictly correct. A navigational database is one in which the logical access to the data in the database is done via the application-level interface or API, It is navigational in the sense that logical relationships are traversed by the application code "navigating" its way through the database. What physical techniques are used to accomplish this, i.e., ISAM, embedded pointers, etc., is almost irrelevant to the discussion. By contrast, a relational database does not provide the application layer with any way to "navigate" through the logical database structure and instead provides a set-level interface for selecting, aggregating and joining data. Relational databases may also use a variety of physical techniques to access data including the same mentioned above, but the important aspect of being "relational" is that the data is accessed relationally, i.e., vie a set query model rather than a navigational model.)
Micro-Kernel Database Engine
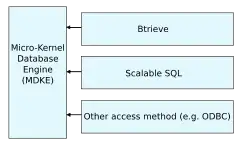
Starting with version 6.15, Pervasive started using a new modular method of separating the database backend from the interface that developers used. They separated the core database operations (like update, write and delete records) from the Btrieve and Scalable SQL modules. By separating the Micro-Kernel Database Engine (MKDE) from the other functions it allowed programmers to use several methods of accessing the database simultaneously. For instance, an application may be created using the Btrieve API and another application that needs to access the same data may use a totally different method, like using Scalable SQL. Because the record primitives have been separated from these methods, both applications can use the MKDE to access the same data file.
The Micro-Kernel Database Engine is unrelated to microkernel operating system kernels.
Paging
The Btrieve file format consists entirely of pages, which is the data that moves between memory and storage media when the engine performs an I/O operation. Versions prior to 6.0 merely used data pages, index pages and a file control record (FCR). The file had an index for searching that linked to physical pages. Beginning with version 6.0 logical pages started to be used, which are pages that are mapped to physical pages (pages at a fixed location in the file) on the disk through the use of a set of page allocation tables (PATs).
File control record
The file control record (FCR) contains important information about Btrieve database files. It holds the page size, the number of pages in current use, the number of keys that can index the file, the number of records in the file and other details. After version 6.0 two FCRs were used for redundancy. A 32-bit usage count field that exists in each FCR is used to determine which FCR was valid to use. Each time an operation is done on a file the field is incremented. The FCR with the highest usage count becomes the valid FCR. The FCR is well described at source samples from Jim Kyle. With the introduction of MKDE version 8, the structure of the FCR page is changed. The page size is now moved within the FCR and is not a regular 32-bit field. Since version 8 you have to calculate the page size by taking the 32-bit field at offset 0x2A and multiply with 256.
Page allocation tables
A page allocation table (PAT) maps the logical pages to the physical pages. Each PAT is just a physical page located at well-defined locations. Like the FCRs, PATs always occur in pairs, with the currently valid copy indicated by having a higher usage count. The first pair of PATs immediately follow the first two FCRs and takes up physical pages 2 and 3. A variable number of other pages follow, and a new pair of PATs in turn follow this. Each PAT has a fixed number of pointers to logical pages, with each entry that is empty having a value of zero.
The amount of logical records that can be stored in the PAT is determined by its page size. Each page pointer in versions 6.x and 7.x of the MKDE takes up 4 bytes of space, and the PAT header takes up 8 bytes, so the amount of logical pages in the PAT becomes:
- Number of logical pages = (Page size ÷ 4) - 8
With the introduction of MKDE version 8, the size of the page header changed and so this formula no longer applies but the principle remains the same.
Pre-image paging vs Shadow paging
Until version 6.0, pre-image paging was used when performing updates to records. It involved the creation of a new "pre-image file" before the changes were made, and then the pages from the original data file were copied into this new pre-image file temporarily. Then the system would make the changes to the original file. Should the update be interrupted and only half the data written to the page, then the page would just be rolled back by the engine by copying the page from the pre-image file back into the corrupted page in the original database file, then the temporary pre-image file would be deleted. The preimage files were given the extension .PRE, so finding these files in the system usually indicated that a transaction had not happened correctly and recovery had not been successful.
Starting in version 6.0, shadow paging was used instead of pre-imaging, and it is still used to this day. Instead of copying the page into a temporary file, the next spare physical location in the database file was found and the page was written to this location. This page is called a shadow page because it still has not had its location written to the file's PAT. Once the update to the shadow page completed, the PAT was updated and the entry recorded in the PAT of the next available and current physical page in the file. However, if a system failure occurred while doing the update to the shadow page the PAT would not be updated and so the change would be dropped because the current and next entry was not updated in the PAT.
The change-over from pre-image paging to shadow-paging caused radical file format changes that broke compatibility between previous versions of Btrieve and version 6.x of the product.
Alternate Collating Sequence pages
Alternate Collating Sequence (ACS) pages are pages that allow records to be sorted in a different order. Collation is the assembly of written information into a standard order. In common usage, this is called alphabetisation, though collation is not limited to ordering letters of the alphabet. For instance, an ACS might allow the sort order to sort in both case-sensitive and case-insensitive order. Prior to version 6.0 only one ACS was able to be stored in the file, however after 6.0 was released more than one ACS page could be associated with a file at any one time.
Extra pages
In version 6.0 and later files, more physical pages can exist than are actually used. This is because with shadow paging some pages in the system may not have an entry in the PAT. These pages are marked as "Extra" pages, and are used up before space for new pages is allocated.
Variable-tail allocation tables
In Btrieve, each page is fixed but a record can be larger than the page size. This means that records often need to be fragmented and spread over many different pages. With very large records this can mean that many hundreds of pages may need to be used in order to store the record. A linked list approach would be able to allow for this fragmentation, but the Btrieve engine would have a hard time reading through sequential records. Therefore, starting with version 6.1, a table is used in the file that stores pointers to each of the pages that make up the data record. This table is called a variable-tail allocation table (VAT).
Indexing

Btrieve uses a b-tree format to store record indexes on particular table columns. The index maps each set of indexed column values to the set of unique identifiers for the rows that have those column values, which provides a quick way to find the rows within a table using the indexed column. B-trees are tree data structures and are very efficient as a mechanism for fast data retrieval. The drawback of a btree is that data must be constantly balanced when it is inserted into the tree, therefore Btrieve only stores the record index as btree to reduce the amount of time it takes to insert and update records. A separate b-tree is kept for each index in the system, and the root node information is kept in the FCR. In Btrieve 6.x a new index can be created at file creation time, or added and dropped after the file is created. Index pages are also created as they are needed. Before Btrieve 6.0 existing key indexes could not be removed, though supplemental indexes could be created and dropped as needed.
Btrieve allows for duplicate key values in an index. Btrieve handles duplicate keys using either a linked duplicate method, or by using a repeating duplicate method (this terminology started being used when version 6.0 was released). The linked duplicate method used a pair of record pointers in the index page itself to point to the head and tail of a doubly linked list of duplicate keys. This meant that the order of the duplicate keys in the list was in the order they were entered. The duplicate key method did not use a linked list, but rather made all the keys unique by creating a new index key and appending the address of the record pointer to the end of the key. This means that the key is retrieved via its position order.
File sharing
When Btrieve needed to do file sharing to gain access to records, two different types of file sharing modes could be used: Single Engine File Sharing (SEFS) mode, and Multi Engine File Sharing (MEFS) mode. SEFS only allowed the clients that accessed that engine to alter the database, other clients that accessed a different engine could not gain access to the database. MEFS allows different clients running under different engines to access the database.
Concurrency
Btrieve was able to handle concurrent transactions in the 6.x series. Before Btrieve 6.0 the engine could only do file level locking or exclusive locking; from 6.0 onward, records could be locked individually. Locking at the record (or page) level was known as concurrent locking. The advantages were obvious: more than one client could access the file at the same time, so long as they weren't trying to access the same record, leading to performance increases. Additionally, other clients could read the locked pages, and would not see any changes to a file involved in a write transaction by another process that had locked the record.
MEFS mode did not completely support concurrent locking. If a client started a concurrent transaction and then tried to perform a write operation to a record, the Btrieve engine would return a status code 85 that indicated that the file was locked — even though a concurrent lock was being used.
System and user transactions
Starting with version 6.15 of Btrieve, a new type of database transaction was introduced called a system transaction, which was separated from user transactions. User transactions are exclusive and concurrent transactions while system transactions are a bundle of non-transactional operations and/or user transactions. System transactions were exclusively used for data-recovery by the MKDE. If a system failure causes data corruption then when the MKDE is restarted it detects all the files that had a failed system transaction and tried to recover them. However, as user transactions might have been lost when the last system transaction was rolled back an option could be set that caused the MKDE to force system transactions that had user transactions to complete when the engine received an "End Operation" request.
References
- Dahunsi, Ayodele (January 1, 1998). Understanding Btrieve and Scaleable SQL4. Clarion Magazine.
- Kyle, Jim (1995). Btrieve complete: a guide for developers and systems administrators. Reading, Massachusetts: Addison-Wesley Publishing Company. ISBN 0-201-48326-2.
- Novell (no date). Components of NetWare Btrieve. Retrieved December 12, 2004.
- Pervasive (1997) . Btrieve for DOS Installation and Operation manual. Product manual.
- Pervasive (1998). Status 96 from a NetWare NLM Application. Pervasive KnowledgeBase article (article ID: BTRTT-97070801). Retrieved December 12, 2004.
- Pervasive (November 1996). Btrieve for Windows NT/Windows 95 Installation and Operation. Product manual.
- C Fiedler (July 2010). btrieve database file access (PageSize detection).
- dbcoretech (July 2010). btrieve recovery utility (open source).