All-to-all (parallel pattern)
In parallel computing, all-to-all (also known as index operation or total exchange) is a collective operation, where each processor sends an individual message to every other processor.
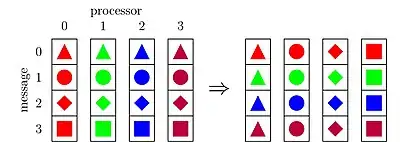
Initially, each processor holds p messages of size m each, and the goal is to exchange the i-th message of processor j with the j-th message of processor i.
The number of communication rounds and the overall communication volume are measures to evaluate the quality of an all-to-all algorithm. We consider a single-ported full-duplex machine throughout this article. On such a machine, an all-to-all algorithm requires at least communication rounds. Further a minimum of units of data is transferred. Optimum for both these measures can not be achieved simultaneously.[1]


Depending on the network topology (fully connected, hypercube, ring), different all-to-all algorithms are required.
All-to-all algorithms based on topology
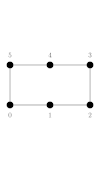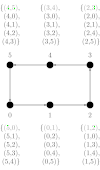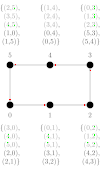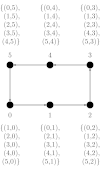
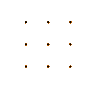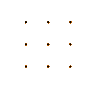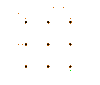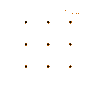
We consider a single-ported machine. The way the data is routed through the network depends on its underlying topology. We take a look at all-to-all algorithms for common network topologies.
Hypercube
A hypercube is a network topology, where two processors share a link, if the hamming distance of their indizies is one. The idea of an all-to-all algorithm is to combine messages belonging to the same subcube, and then distribute them.
Ring
An all-to-all algorithm in a ring topology is very intuitive. Initially a processor sends a message of size m(p-1) to one of its neighbors. Communication is performed in the same direction on all processors. When a processor receives a message, he extracts the part that belongs to him and forwards the remainder of the message to the next neighbor. After (p-1) communication rounds, every message is distributed to its destination.
The time taken by this algorithm is .[2] Here is the startup cost for a communication, and is the cost of transmitting a unit of data. This term can further be improved when half of the messages are sent in one and the other half in the other direction. This way, messages arrive earlier at their destination.



Mesh
For a mesh we look at a mesh. This algorithm is easily adaptable for any mesh. An all-to-all algorithm in a mesh consists of two communication phases. First, each processors groups the messages into groups, each containing messages. Messages are in the same group, if their destined processors share the same row. Next, an all-to-all operation among rows is performed. Each processor now holds all relevant information for processors in his column. Again, the messages need to be rearranged. After another all-to-all operation, this time in respect to columns, each processor ends up with its messages.


The overall time of communication for this algorithm is . Additionally, time for the local rearrangement of messages adds to the overall runtime of the algorithm.

1-factor algorithm
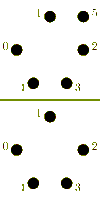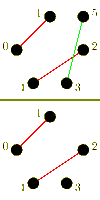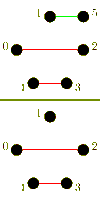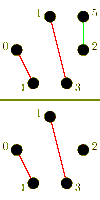
Again, we consider a single-ported machine. A trivial algorithm, is to send (p-1) asynchronous messages into the network for each processor. The performance of this algorithm is poor, which is due to congestion arising because of the bisection width of the network.[3] More sophisticated algorithms combine messages to reduce the number of send operations and try to control congestion.
For large messages, the cost of a startup is small compared to the cost of transmitting the payload. It is faster to send messages directly to their destination. In the following algorithm an all-to-all algorithm is performed using (p-1) one-to-one routings.
//p odd: // pe index for i:=0 to p-1 do Exchange data with PE


//p even: // pe index for i:=0 to p-2 do idle:= if j=p-1 then exchange data with PE idle else if j=idle then exchange data with pe p-1 else exchange data with PE


The algorithm has a different behavior, whether p is odd or even. In case p is odd, one processor is idle in each iteration. For an even p, this idle processor communicates with the processor with index p-1. The total time taken is for an even p, and for an odd p respectively.


Instead of pairing processor j with processor in iteration i, we can also use the exclusive-or of j and i to determine a mapping. This approach requires p to be a power of two. Depending on the underlying topology of the network, one approach might be superior to the other. The exclusive or approach is superior, when performing pairwise one-to-one routings in a hypercube or fat-tree.[4]

References
- Bruck, Jehoshua; Ho, Ching-Tien; Kipnis, Shlomo; Weathersby, Derrick (1997). "Efficient Algorithms for All-to-All Communications in Multiport Message-Passing Systems" (PDF). IEEE Transactions on Parallel and Distributed Systems. 8 (11): 1143–1156. doi:10.1109/71.642949.
- Grama, Ananth (2003). Introduction to parallel computing.
- Hambrusch, Susanne E.; Hameed, Farooq; Khokhar, Ashfaq A. (May 1995). "Communication operations on coarse-grained mesh architectures". Parallel Computing. 21 (5): 731–751. doi:10.1016/0167-8191(94)00110-V.
- Thakur, Rajeev; Choudhary, Alok (26–29 April 1994). All-to-All Communication on Meshes with Wormhole Routing. Proceedings of 8th International Parallel Processing Symposium. Cancun, Mexico.